c++ misc
05 February 2021
Pointer陷阱
Q1
int B = 2;
void func(int *p){p = &B;}
int main(){
int A = 1, C = 3;
int *ptrA = &A;
func(ptrA);
printf("%d\n", *ptrA);
return 0;
}
output: 1
原因: func在calling convention中是會複製一份指標變數,而他只到的地方跟ptrA是同樣的地方,等於現在有兩個指標變數都指向變數A的位址,但在func做的是是把裡面的這個指標變數指向B這個位址,但此時ptrA仍然是指向變數A
改法: 如果希望func確切把ptrA指向的地方改為B, 那就必須徹徹底底的把ptrA的指向位址改向B而不是複製一個指標來做這件事,因此改法是先把func的參數改成**p, 然後傳入&ptrA, 這樣等於func吃一個指向指標位址的指標變數,所以*p就會是ptrA,我們就可以操控ptrA要指向哪裡
int B = 2;
void func(int **p){ *p = &B; }
int main(){
int A = 1, C = 3;
int *ptrA = &A;
func(&ptrA);
printf("%d\n", *ptrA);
return 0;
}
output: 2
Call by reference
主要是利用reference operator來做的, 為C++特有的operator, 實作細節應該是利用alias 讓兩個變數名稱指向同個記憶體位置
int &M = n;
代表M的位址指向n的位址, 這裡的&是reference operator
這樣M的值修改也會跟著修改n的值, 所以函式傳遞參數時也是使用reference operator
相對的
int m = &n; 則是address operator
這裡m的值會是n的記憶體位置的整數值
reference operator的幾個特性:
- 再initialize時一定要指到某個變數,不能像pointer一樣init時為NULL
- init完後指到的位置就不能再變
- 在for loop or function call時很好用, 能避免大物件的copy
Reference:
geekforgeek
function pointer
宣告一個指標指向function的instance
void func1(int a, int b)
void *(funcptr)(int,int) 這等於是一個function pointer叫做funcptr 他會指到接收兩個int當參數, 回傳void的function
funcptr = &func1
著名例子就是qsort這種可以定義最後comparison function時, function實作的參數就會用到function pointer
void qsort(void* base, size_t n, size_t size, int (*cmp)(const void*, const void*));
有一個function pointer叫做cmp指到接收兩個參數,回傳int的function
另一個常見的usecase就是multithread中的callback function, 在要平行化的function宣告一個function pointer, 這個function pointer接收的function就是在平行化的function做完後執行這個callback function 他可以根據使用者傳入的function執行不同的function
最後一種就是refactor時常用的, 避免過多的if else, 用function pointer更簡潔
加碼: 閱讀複雜的pointer的句子方法
void ** (*d) (int &, char*) -> 一個function pointer d, 接收一個reference int, 跟char pointer 回傳一個兩層pointer
reference: 閱讀複雜pointer的句子
Constructor & Destructor
用於class, struct建立時預先跑的一段function來初始化class, struct(通常是初始化變數值). 基本上struct跟class是一樣的東西, 可以用variable, member function, contructor, destructor,但struct所有member function, variable都是public, 沒有private, 此外他也沒有繼承的功能
struct trie{
struct trie *next[26];
int val;
trie() val(0){
for(int i = 0 ; i <26 ; i++){
this->next[i] = NULL;
}
}
~trie(){
for(int i = 0 ; i < 26 ; i++){
if(this->next[i] != NULL) delete this->next[i];
}
}
}
constructor就是一個沒有回傳值的function, function name要是class name或struct name, constructor宣告是可以overload的, 就是可以有複數個constructor, 只要他的paramter不同即可.
Destructor就是在建立這個class/struct的function結束時, 會呼叫destructor來刪除物件, 如果物件本身都是靜態記憶體配置(沒有用到malloc, new) 那其實有沒有destructor通常是沒差, 主要是有動態配置記憶體, function結束,用完時要把它清掉, 不然就memory leak. 如果一個function裡有多個constructor呼叫,那function結束時, destructor呼叫的順序會是反序(stack FILO的方式, 最晚建立的物件會最先被呼叫desctructor)
另一點值得注意的是desctructor沒有overload,也就是一個class只會有一個descturctor,他也不吃任何參數。但destructor可以override,也就是它可以是virtual function, 每個class可以有自己的desctructor然後是繼承自base class, 這樣也比較好,避免明明是在derived class卻呼叫到base class desctructor的窘境。
Class裡的static function是就算class object還沒有建立還是能夠使用的function,但靜態函數不能夠存取class內的非靜態成員資料,一個原因當然是使用static function時不一定有物件建立了
class A{
static int getA(){...};
}
A::getA() 使用class static function時要使用::這個operator來使用
Class裡的static variable是所有物件的共用變數而不屬於任一個物件,所以他可以被大家存取,static variable也不能使用this, 因為他不屬於物件的一部分
class A{
static int c;
}
A::c = 4; 可以在不用建立class object時就初始化或修改值
Constructor
copy constructor基本上就是對每個element呼叫memcpy, 對於一般data type沒什麼問題,但對於指標,呼叫memcpy基本上只複製指標這個東西和他指向的位置,並不是複製他的memory data, 所以導致shallow copy. Shallow copy除了非預期的行為外,也很容易在destructor時發生double free的問題,因為兩個object instance內的member都指向同個memory data.
Default and Delete
C++11多了兩個keyword: default and delete, 主要用於constructor部分
一般而言,如果一個class沒有宣告constructor, 編譯器會自動幫忙產生三個constructor, default constructor, copy constructor, assign constructor。 而所謂的default constructor的部分,如果user有宣告其他的constructor,就不會有他,因此如果user希望能夠保留這個default constructor, 就要加=default的字串,這樣就可以確保編譯器還是會加這個constructor。
delete關鍵字則相反,當我不希望compiler幫我建立這些constructor時使用,例如某個class希望他是non-copyable, 那就希望不要有copy constructor,所以就會用delete關鍵字來避免編譯器自動產生constructor
class A{
A() = default;
A(int a);
A(const A&) = delete;
}
Reference: cnblog
Initialize list
在constructor建立物件時,一種init class member的方式,除了語法糖以外,他的主要功能有以下
class A::A(int a) : b(a);
Default Initialize and Value Initialize
Reference:
Value Initialize
Default Initialize
StackOverflow Paranthesis after object declare
c++建立物件以兩種方式: default initialize跟value initialize
Default initialize指建立好空間給物件,因此這種使用上要注意,建立的物件事uninit的
value initialize則會把物件的data member也改成指定值
Default Initialize
B b;
B = new B();
這兩種方式建立的物件都是uninit的
default contructor還有一種情況會發生: 被contructor的initialize list忽略的class member也會被default initialize
Value Initialize
B b();
B b{};
B b = b();
B b = new B();
這種方式建立的物件就會value init, 如果沒限定就是zero init, 把值設定成0
friend class/method
friend function代表該function雖然宣告在class內,但跟static一樣該function不屬於該class, 外部的class或其他人都可以直接使用該function, 而friend function一個很大用處是雖然他不屬於class, 但他可以存取class object內的所有成員(public, private…都可以)
class A{
int fires;
friend int getfires(Fires obj){return obj.fires;}
};
class B{
void print(A &obj){
cout<< getfires(obj)
}
}
int main(){
A f;
getfires(obj)
}
friend class, 如果class A是class B的friend, 則class B可以使用class A的任何成員(public,private…)
class A{
friend class B;
}
class B{}
- friend是單向的, 也就是上述例子class B可以使用class A的任何成員, 但class A不能使用class B的任意成員
- friend的關係是不可轉移的,例如class A是class B的friend, class B是class C的friend, 但class C不能夠直接存取class A的內容
- friend關係不能被繼承,如果class A是class B的friend,繼承class B的class不能使用class A的成員
Virtual Function
Virtual Function是為了實現C++裡的OOP多型的指令。
多型的概念是在於對於有繼承關係的Class, 可以對於某些function, derived class跟base class有不同的實作跟行為。 做法就是在base class把想要多型(根據class有不同實作的function)宣告virtual, 然後再derived class就可以override這些function
使用Virtual Function方法是宣告一個base class pointer, 然後這個pointer會根據指向的derived class種類來run-time link virtual function, 所以pointer指到derived class A,那這個pointer呼叫virtual function時他就會使用到class A的function實做.
Destructor也可以使用virtual function, 這樣在derived class就可以使用自己的destructor然後也會呼叫到base class的desctructor, 不然如果只有base class有destructor, 然後derived class沒有的話,會呼叫到base class的destructor, 那就有可能導致潛在的memory leak問題, 例如derived class自己擁有的variable使用了new指令, 而base class如果沒有這個變數的話,只呼叫base class constructor會造成memory leak, 這些new的變數不會被清掉。
class X{
virtual void run(){
puts("X");
}
}
class A:X{
void run(){
puts("A");
}
}
int main(){
X *ptr;
A sample;
ptr = &sample;
ptr->run() // output A
}
pure virtual function的宣告方式如下, 即在function declaration地方直接後面接 = 0, 這樣代表這個class是一個interface的概念。即有pure virtual function的class不能夠建立object, 而繼承他的class就必須去實作這個function。
class A{
virtual int print()=0;
}
Virtual Function的特色就是這些function是在run-time link到code section而不是compile time link, 因為他是看指到哪個 實作概念上就是對於這些function會在symbol table上一開始先不填上code section, 而是在跑起來時,根據指到的derived class再填入function的位址。而實際上就是class在建立時會有一個欄位叫做vptr,他會指向這個class的vtable, vtable就是紀錄各個virtual function他指向的code section
此外在程式中, 並沒有class, struct的概念, 他們都是變數, 以primitive type存在運行程式的記憶體中, 所以例如class, struct的建立其實都是編譯時會給他們default的一個function(這個function在code section), 這個function在gdb上看名稱是亂碼, 但基本上就是struct, class的constructor, 自己宣告的constructor同理, 只是皆不同參數, gdb上看也是亂碼函式, 而class的method其實就是function, 所以也是存在code section, 只是method不同於其他function是他編譯時會自動補上第一個參數, this來指名呼叫這個method的object位址, 然後就可以通過this來操控object裡的變數
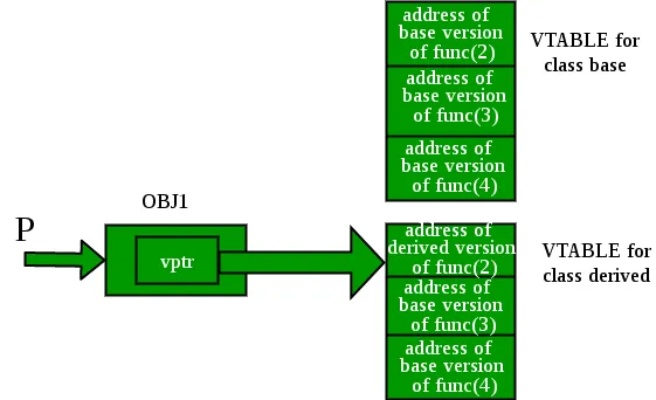
Reference: vptr,vtable</br> cpp virtual table</br> where does class and method store
Exception
C++有一個stdexcept的header可以用, 裡面定義了一些常見的exception(如logic_error, out_of_range, overflow_error, runtime_error等等)
這些exception class都是繼承自exception這個base class,裡面有一個what的virtual function, 讓各個exception class能夠specify自己的details, 所以可以catch(exception e)然後呼叫e.what()來看細節
Stack unwinding: 用於exception handling, 基本上就是throw exception到catch中間可能會有多層function call(try/catch block跟throw的function中間可能很多層function call), 一旦發生thro exception, throw的function block到catch的function block之間的function, 他們在stack的資料都會被清掉,有點像是function return的感覺,但他實際上是只有清掉這些function在stack上的資料,並沒有真的正常的執行throw exception後面的程式碼,也沒有進行return. 但正常的stack中有的class,他們的 constructor, desctructor會被呼叫, 所以在class object裡面new的東西,理論上發生stack unwinding還是會call desctructor然後delete這些dynamic allocation.
guidlines:
- 如果某些錯誤從來就不應該出現,使用assert,例如發生這個錯誤就是要噴出一些明顯的訊息和讓程式terminate, 那就直接用assert就好. exception應該在程式正確執行時仍然可能發生的錯誤, 如input值範圍, file not found, out of memory.
- throw exception by value, caught them by reference
- 不要再function後面加Exception keywords和說明可能的exception
- Exception handle要很小心,stack unwinding可能會導致memory leak, 如果多層function call,裡面某層發生exception的function是由某個外層的function catch, 那中間這些function進行stack unwinding,中間的function如果有new, delete東西, 很容易會沒call到delete導致memory leak. 又例如function allocate的東西後throw exception, 就很有可能沒執行到delete導致memroy leak, 或者catch沒處理好garbage collection, 沒free掉function裡的resource直接跳到其他地方.
- keep resource simple, 使用smart pointer來allocate resource
- 要值得注意的是constructor如果發生exception, desctructor不會被invoke, 不要讓exception escape from desctructor, exception這裡發生一定要在這裡做完
Reference:
cplusplus
microsoft最佳使用exception的時機
stack unwinding during exception
特殊變數
Volatile
因為compiler會對程式編譯做一定的優化, 例如for迴圈可能會把它unfold或者把迴圈加法變成乘法, 這種行為在multithread環境會有潛在性的問題, 或者是kernel exception/interrupt handler會修改到的變數, 那這時候某些變數也要用volatile避免優化導致變數值跟預期中的不同, 因此volatile的變數就是告訴compiler不要對這個變數的行為做優化, 避免再multithread環境出問題
Reference: liquid0118
Restrict
用來做指標的優化, 如果確定指標是唯一指向data的指標, 不會有其他pointer、變數來存取這個data, 那可以把pointer宣告restrict來提升效能, 優化包括在for loop裡面就可以把restrict pointer的運算unfold, 因為不用擔心其他程式碼會來修改到這份資料, 所以也可以做instruction reordering
explicit
主要用於只有一個argument的constructor, 用途在於避免C++ 自己進行implicit compile導致可能的錯誤。
如果參數型態錯誤的話,C++ compiler會自動幫user做一次參數轉型。但參數型態錯誤這可能是一個bug,而compiler沒抓出來,這樣導致原本不應該傳進去的參數被傳進去,導致constructor建立物件會有問題。
如果constructor宣告explicit的話,這種參數型態錯誤,就會變成compile error而不會自動轉型。
struct Foo {
// Single parameter constructor, can be used as an implicit conversion.
// Such a constructor is called "converting constructor".
Foo(int x) {}
};
struct Faz {
// Also a converting constructor.
Faz(Foo foo) {}
};
// The parameter is of type Foo, not of type int, so it looks like
// we have to pass a Foo.
void bar(Foo foo) {};
int main() {
// However, the converting constructor allows us to pass an int.
bar(42);
// Also allowed thanks to the converting constructor.
Foo foo = 42;
// Error! This would require two conversions (int -> Foo -> Faz).
Faz faz = 42;
}
Reference: What does the explicit keyword mean
Why do we need header file?
What is header file?
header file跟cpp檔最大的差異在pre-processing階段就會被處理,在這個階段,macro會被展開,因此header file裡面寫的東西都會被複製一份到include他的cpp檔,因此建議header file都以declaration為主,不然implement在這裡的話內容太多,每個cpp檔都會複製同樣的implementation是不必要的,很佔空間,除非是像template這種東西才能夠寫在裡面。
Declarations and Definition
C++的entity (variable, function…)分成declaration跟definition,任何entity在使用前一定要先declare.
void func(); //forward declaration
int main(){
func(); //如果沒有forward declare,會報錯
}
void func(){...}
在現在大型project實行modularize的情況下,要在file A使用file B的東西,一個方法就是透過forward declaration, 或者是寫在.h檔裡面,讓compiler把.h裡面的declaration複製進來此cpp
Extern變數: 大型專案內會有多個compile unit(即每個cpp檔都是一個compile unit, 最後透過linker把這些產生的obj檔連成exe), 而當symbol是定義在另一個compile unit時, linker在link多個obj檔時會沒辦法resolve那個symbol產生error, 因此這時候就要對那個變數使用extern的關鍵字,跟compiler說當前這個變數是宣告在其他的scope或compile unit, 讓linker去其他compile unit找。
Definition的意思是某些entity(structure, class, function),他們會需要有更多的細節, compiler才能夠產出machine code來達到預期的目的,而這些細節稱為definition.
microsoft docs:Declaration and definition
ODR (One Definition Rule)
一個Entity在一個程式裡只能有一個definition, 不然會出錯,最常見是function裡面定義了某些structure, class,如果一個執行檔裡多個檔案同時include此header file, 就會產生error, 因為等於同一個structure在這個執行檔裡被定義多次(多個檔案include header, header把structure,class的definition複製到每個檔案中),此時就要用#ifndef,#endif,或者#pragma once,在header中加入這些東西可以避免他被複製多次到執行檔中導致重複定義。
Back to the question
為什麼要header file: 因為c++設計上使用entity前需要declare, 而又需要modularize的狀況下,就產生的.h檔這種做法,Modularization,讓程式能夠拆小,並且重複使用程式碼,只inlude會用到的函數而不是所有的程式碼都在單一檔案