Cache Coherence
06 May 2019
背景
狀況一
再多CPU的系統中,每個CPU有自己的cache,假設CPU0修改某個變數值,而另一個CPU1又要接著用那個資料,但CPU0修改的變數值只改在自己的local cache,此時CPU2讀取變數是讀到舊得值而不是CPU0修改過後的變數值。
狀況二
CPU0,CPU1同時對某個變數做修改,那寫回memory時應該以哪個為主,或者存取該變數值時,要以哪個值為主。
naive 解法: braodcast
當某個值被某個CPU修改時,會把資料寫回memory。此外,還會把這個signal送到所有的cpu,檢查該變數值在不在cache裡,再的話就把他invalid掉,當新的CPU要用那個變數時,因為是invalid,所以等於是cache miss,cpu就會送requests去下面找,requests會包含指令、memory address。而下面收到訊息後會把變數cache miss值傳給其他CPU(透過bus),CPU有valid的該變數就會寫回memory然後傳給cache miss的CPU。
因為bus一次只能傳輸一份資料,所以一次就是一個cache傳signal。也因此,如果很多CPU同時改某個變數,那就要照順序做request、修改,每次一個CPU把資料寫回memory,不會有兩個CPU同時用bus傳資料的問題
MSI Cache coherence
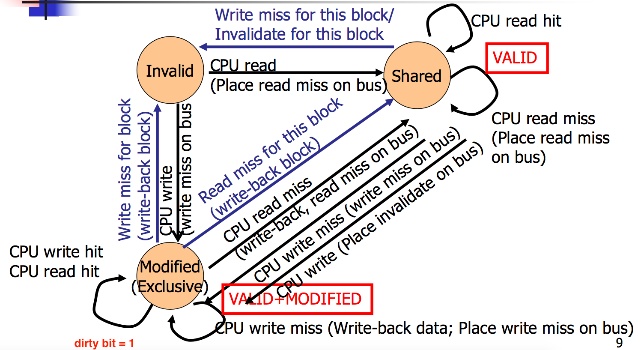
基於上述naive解法提出的方法,用state machine來表示,一個CPU cache就有一個這樣的state。
Inavlid state
either CPU cache裡面的資料被其他CPU修改過或者資料不在cache裡(valid bit = 0)
Shared
valid的資料,可以讀但不能寫資料(valid bit = 1, dirty bit = 0)
Modified state
可以local讀寫該資料(valid bit = 1, dirty bit = 1),要保證其他cache沒有這個資料,那就可以local端改寫
對於一個變數、一筆資料,可以有多個CPU Cache在shared state,但當有一個CPU Cache在Modified state時,其他CPU Cache一定要在invalid state
轉移
從invalid state轉成modify state
就是要把valid bit變成1,如果能變成modify state就能進行local端讀寫
轉移方法為把write requests(cache miss)放到bus上(像線上面所說)
因為一但發write requests就可以確定其他CPU Cache都沒有這份資料,或者這資料被轉成valid bit=0,這種狀況就可以修改CPU cache裡該data值。
Modify state to invalid state
假設 CPU0想修改某個值a,他發requests給其他所有CPU後,此時所有有a值得CPU cache,他們對於變數a的valid bit = 0,此外如果原本某CPU對變數值是在Modify State,就還要把資料寫回memory,之後CPU0就可以local修改這個值在寫回memory。
此時如果CPU1也想修改值a,他也會發requests,這時原本CPU0在modify state,因為收到bus傳來的這個requests,所以a的變數的valid bit變成0,state從modify state變成invalid state。
如果假設某CPU2這時對於變數值a是modify state,他會先把修改的變數值寫回memory在把變數值改成invalid
另一方面,CPU1則是從invalid state變成modify state
Modify state to Shared state
假設現在在modify state,但我們是讀資料不是寫資料,那就會移到shared state,會先perform一次write back接著就移到shared state,dirty bit = 0。
對於一筆資料,可以有多個cpu cache在shared state,但只能有一個CPU cache在modify state
Invalid state to Shared state
CPU要讀資料時發生cache miss時,會送read requests。
Shared state to Invalid state
如果CPU收到bus傳來某個變數值要被寫,此時就會把那筆資料的valid bit變成0,cpu cache對於那筆資料從Shared state變成Invalid state。
Shared state to Modified state
在shared state不能夠寫資料,dirty bit = 0,因此要寫資料cpu cache會從shared state轉成Modified state,此時就要發write requests到bus,才能轉成modified state,把其他有這筆資料的CPU Cache都改成valid bit = 0
Reference
MESI Protocol
MSI的一個重點是,只要有寫資料轉成modify state時,就一定要送invalidate signal給其他CPU(因為本身這個CPU也不知道其他CPU是否有這筆資料),就算其他CPU都沒有那筆資料或者很少CPU有那筆資料,但invalidation signal就是會透過bus broadcast。
而就是因為各種requests都要透過bus,所以就會導致不必要的傳輸,浪費資源減慢速度。
新增一個Exclusive state來解決上述問題,減少不必要的invalidation signal。
Exclusive state
讓CPU Cache能夠read write資料,對一筆資料,一次只能有一個CPU Cache在這個state,基本上就是代表clean state。就是所有CPU只有這個這個state的CPU有這筆資料,他可以隨意讀寫。
如果有其他cpu cache有這筆資料時,就會從exclusive state變成Invalid state或者shared state
Exclusive state to Invalid state
如果CPU在exclusive state寫資料時發生write miss,代表valid bit = 0,因此變成Invalid state
Exclusive state to Modify State
如果從讀資料變成寫資料,就變成Modified state
Exclusive state to Shared state
如果發生read miss就從Exclusive state變成Shared state
Invalid state to Exclusive State
當CPU想要讀資料,發出read requests時,沒收到任何response,他就是exclusively 擁有這筆資料,進入exclusive state,反之則進入Shared state。
False sharing
當兩個CPU(CPU0,CPU1)有兩筆資料A,B,但他們常綁在一起,一起修改到(同個cache line),例如invalid時就會把A,B同時變成invalid,或者兩個同時valid。因此當CPU0修改A且CPU1修改B時,就會發生ping pong不斷修改停不下來,因為會發生兩者一起修改的狀況。
cc-NUMA
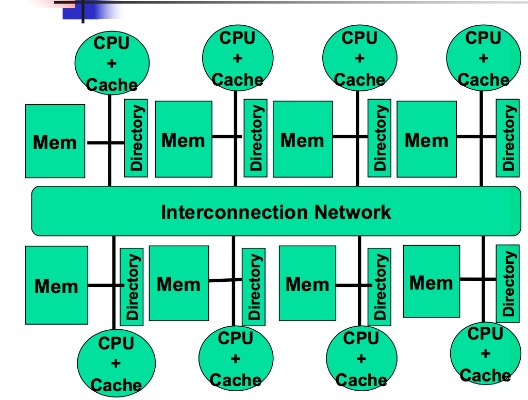
Distributed shared memory architecure
MSI,MESI最大的問題就是用bus來broadcast資訊給memory,其他CPU。這樣能做到平行化存取的效率很低,bus一次只能處理一個request/signal。
因此cc-NUMA就用interconnection network把各個CPU-Cache,memory連再一起,這樣就不會受到bus一次只能處裡一個signal / request的問題。每個CPU有一個Directory架構幫忙記錄每個資料是屬於哪個CPU。
如果有CPU修改變數值的話,則Directory會告訴需要把變數值轉成valid bit = 0的CPU。然後這部分可以透過interconnection network快速達成。
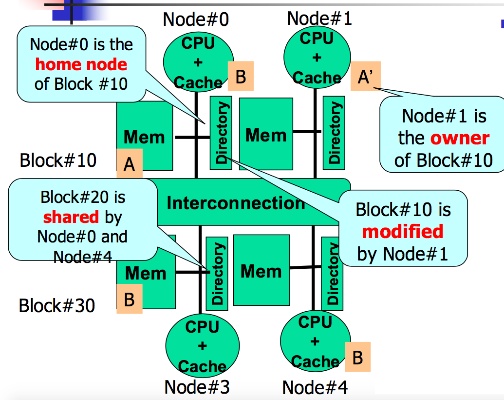
Home Node
描述某個資料的home node就是那筆資料現在是在哪個CPU的memory。
只要有就好,所以一個變數可以有很多Home Node。相當於Shared state的概念
同MSI架構,如果一個Home node從Shared state要轉成Modified State,就會發write miss給所有其他Home Node。
Owner Node
有最新的變數值得Node,即剛寫完該變數值得CPU。修改完後跟MSI架構一樣,要通知所有Home node把資料改成invalid。
也因此,當其他Node要存取某個資料發生read miss時,就可以透過directory去找owner node取得最新資料
SMP and cc-NUMA
Communicaation
- SMP: broadcast
- cc-NUMA: 直接透過internetwork傳給需要的Node,cc-NUMA scalability更高(可以handle更多Node)
cost for maintenance
cc-NUMA latency比SMP高,因為要傳給多個Node,不是broadcast
multi-processor的難題
以TSO為例(Total Store ordering)
此種例子CPU有機會在現在寫進memory的指令完成前,先讀後面指令資料
Init A,B = 0
Process 1
A = 1
print(B)
Process 2
B = 1
print(A)
可能得輸出值為(1,1),(0,1),(1,0),(0,0)
0,0可能原因為TSO可以允許多個指令同時執行,當A=1還在assign時如果後面先做出來,就會print(B),B為0。process 2同理
解法
有些硬體、程式語言有一些solution,或者使用mutex lock