Tomasulo algorithm & Speculative Execution
07 May 2019
通常用於high performance computing,這個演算法能達到Instruction Level Parallelism(ILP)
youtube video
傳統CPU design是一次decode一個instruction,餵進去ALU裡做運算寫回register或memory,pipeline可以使不同的stage非同步進行。但不論該運算為何(可能只是單純ALU運算),他會在所有stage都佔一個cycle,他還是會佔據memory read/write那個stage的一個cycle。
而Tomasulo algorithm的架構是,我可以同時執行多個instruction,如下圖,我們會把整個流程拆開,有memory read write的部分,有加法器的部分、有乘法器的部分,這樣分流後,進行加法的運算就不用特別跑去memory那個path。而各個單位(加法器、乘法、memory)都會有自己的reservation station,就是queue住目前運算的指令,只要register available,queue在reservation的指令就可以運作,因為整個系統內可以有多個加法器、乘法器。
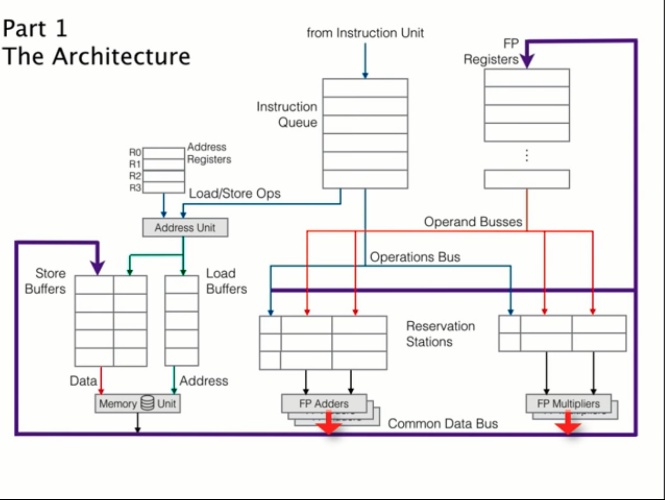
但這樣分開加法、乘法、記憶體讀寫的方式讓其達到能平行運算就會導致out-of-order execution。因為memory讀寫很花時間,所以可能memory還沒讀完,後面指令先做加法、乘法,但此時的memory資料還沒更新。所以得到的值會是錯的。所以有另一個register table,紀錄每個register現在是不是available。要所有指令的register都被free才能夠進行該instruction。當一個指令執行時,src register, dst register都會被mark busy。
最後有一個Common Data Bus(CDB),相當於pipeline(data forwarding)的部分,他可以連接到各個register table或reservation table,可以馬上把剛出爐的新的值放進去reservation table或register table,如果register or reservation有subscribe那他就會讀取CDB傳來的資料。
但雖然有用register table來避免data hazard,但還是沒辦法避免branch prediction的問題,因為branch predict要不要跳可能花很多時間,但硬體會先決定先繼續執行接續的instruction,可能執行完數個後才得知要跳,此時就還是需要有roll-back機制
Execute
- Load/store are maintained in program order
- 所有instruction要等branch弄完確定要不要跳
Reorder Buffer(Speculative Execution)
在Instruction level parallelism(ILP)時,常常遇到branch execution會導致執行錯誤的instruction(branch prediction錯誤),導致這些錯誤執行的指令要roll back,Reorder Buffer就是用來處理ILP的branch prediction error的問題。
並且確保in-order execution(如果有read,write到memory,register時)
write results時,只會把結果寫到ROB,reservation station,但要等到commit才會真的寫進memory或者register file
如果branch prediction錯的話,會把reservation station, reorder buffer都清空,從正確指令開始執行
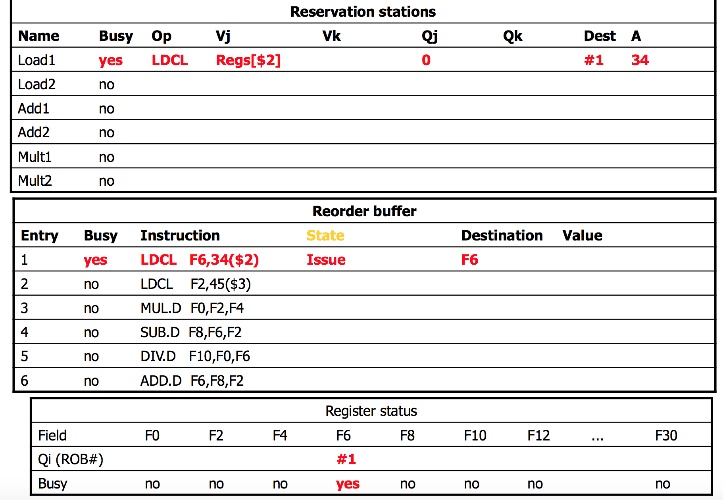
上述reorder buffer table有兩個pointer: commit, issue
- commit: 決定
- issue: 下個instruction要寫哪裡,寫進reservation table的register是寫在這個pointer的地方
此外register table也多一個欄位,除了紀錄register是否正在使用外,並且記錄使用中的register是對應到哪個Reorder buffer欄位
- Qj,Qk: source為reservation station的欄位
- Vj,Vk: source的值
Tomasulo with ROB 流程
基本上就是多把資料寫去ROB,然候多一個commit的動作,確保是沒錯的 然後commit順序就是ROB list的順序,不能out-of-order commit
- dispatch(Issue): 把指令寫進reservation station,並且記錄dst register到rob,必要時在ROB做register renaming
- Execute: 執行該instruction,不用在乎branch prediction的問題
- Write Result: 把結果寫到CDB、reservation station, ROB,但不會跑去reigster table,計算出來的address, value先保存在ROB
- Commit:
- commit: update register value
- store instruction: update memory
- flush: flush ROB and restart the correct path(branch prediction failure)
Branch Prediction
Introduction
在MIPS中感覺還好,如果加上pipelining,Branch prediction造成的delay也不過就1,2兩個stalk而已。 但在現代的CPU架構下有兩個問題。
- 現在CPU為了達到更好的pipelining,會把過程切成更多的stage(不只五個),等於在CPU硬體架構裡能夠同時處理更多的instruction,那這樣一但delay,造成的overhead就會很大。
- 在Tomasulo的架構下,同時可以有多個指令同時執行,如果用insert stalk的方式的話,那會使硬體規劃非常複雜,要知道有幾個instruction在跑,要在哪裡塞一個stalk。
所以開發出了想辦法提高Branch prediction準確率的方法,如果準確率夠高,那整體而言效率會比insert一個stalk好很多。
Branch Prediction Buffer
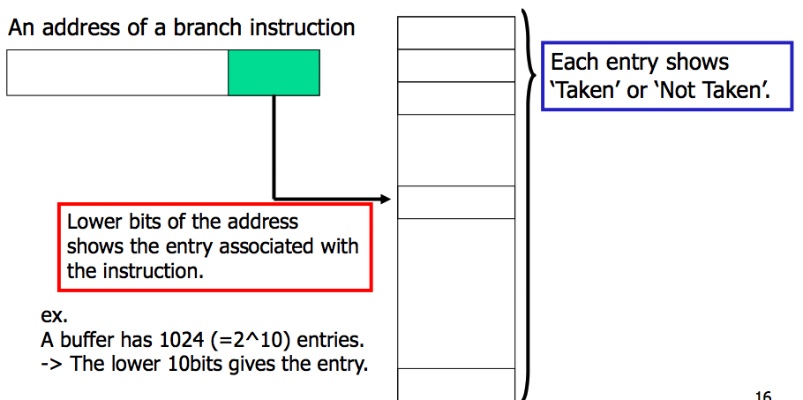
一個程式裡面可以有多個Branch,所以要記錄每個branch的jmp,not jmp的歷史時,就要有Buffer。
作法就是取branch程式區段的位址把他mod到Buffer的格子裡(跟memory概念差不多),例如總共Buffer有1024個entry,那就把branch的address mod 1024,或者說取後面10個bits,那branch的jmp, no jmp歷史紀錄就存在這個entry裡
n-bits Branch Prediction
基本上就是根據這個branch前n次的結果來決定下次要jmp還是不jmp。
最常見的是1,2 bits。
1 bit Branch prediction
1 bit就是上次如果猜錯,下次就換猜另一個選項,如果猜對那就繼續猜那個選項,就是如此單純。
圓圈內T代表猜True,NT代表猜Not True。
線上的T,NT代表猜對還猜錯
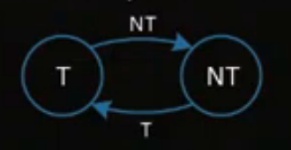
顯而易見的缺點是,如果遇到多層的for迴圈時,那只要每個迴圈一結束當下一定會猜錯兩次,跳出去迴圈那次猜錯(因為不應該jmp回該層回圈起點),重新跳進迴圈那次猜錯(因為上次猜jmp猜錯,所以下次換猜不jmp,但是這個迴圈是新的一輪,所以應該還是要jmp)
而這種多層迴圈在程式中又很常見,所以會很嚴重影響效率,因此有了2 bit Branch Prediction
2 bit Branch Prediction
等於對猜錯多了一點容忍空間,第一次猜錯我還是照猜一樣的選擇,下次猜錯我就換猜另一個,流程圖如下
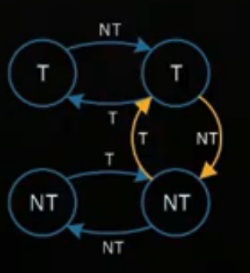
Global Branch Prediction
不同的Branch間可能比此會有關係,所以Global Branch Prediction就把這層關係拿進來考量。
例如下式,第一個branch有進去的話,第二個branch一定會進去。
if(a == 1) b = 1;
if(b == 1){...}
最常見的是(2,2) branch predictor,取兩個branch然後各個branch採用2-bit branch predictor。 方法可以是自己規劃何時要採用哪個branch的結果,如果猜錯predictor要怎麼更新。
Global Branch Prediction也可以是多個branch做ensemble的方式,例如xor看是要不要jmp之類的,和紀錄global history之類的。
TAGE
除了根據global的資訊外,也根據長期的branch history來做判斷這次要不要跳,做法是記錄多次的branch prediction,然後新來的branch就拿來跟各次的branch history的結果做multiplexer之類的來得到要不要跳的結果
Branch Target Buffer(BTB)
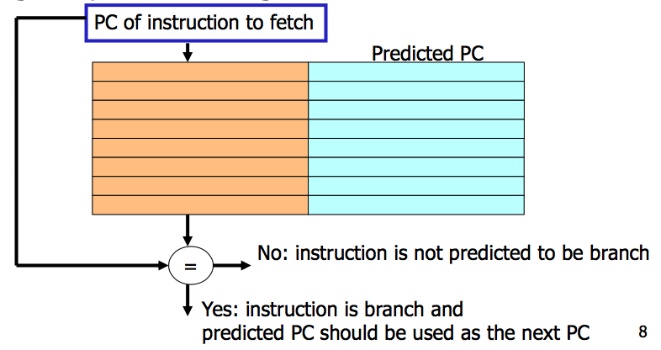
紀錄要跳的Branch指令跟對應要跳的addrsess
Branch Predictor只決定要不要跳,但沒說明要跳到哪,所以這個buffer紀錄對應的branch instructions應該要跳到哪。每當程式走過一個branch instruction然後是要跳的,就會把對應的branch instruction和要跳的address紀錄到BTB裡。
因此BTB只紀錄會predict要跳的branch instruction跟對應address。如果instruction不會跳,不用特別紀錄在這裡,因為沒要跳,不用predict Program counter去的address。
所以遇到branch且判斷要跳時,PC就會去BTB裡找有沒有對應的instruction,有的話讀取後面的address,如果沒有要跳,either這個branch沒遇過或者這個branch predict結果是不跳的。
但當然預測錯的話還是有penalty,然後可能要把BTB裡面該branch instruction清掉。
BTB會需要另外一個buffer,所以會確實是一個成本,所以絕對沒辦法記錄所有branch。但他能在很早的時候就判斷branch該不該跳,要跳到哪。所以這方面又可以省很多資源。甚至可以在IF(Instruction fetch)就判斷要不要跳,連instruction decode都不用。因為BTB的key就是instruction的address。
Loop Unrolling
把迴圈拆開成指令集,Compiler編譯時常用的優化方法,減少branch數量,增加程式Instruction level parallism。
Reference
Physical Register Renaming
- Alternative approach with Register renaming with ROB(一個利用physical address rename,一個用ROB rename)
- A large register file存speculative, non-speculative的值(ROB只存speculative值)
原本renaming with ROB的做法,會把speculative的值存在ROB裡,所以等於多了很多讀寫,然後這些資料又會運算候又要forward到ROB,reservation station,多了很多讀寫。
但是physical register renaming方法不用存另外再把speculative value寫進ROB裡面,只要寫前一個register(存branch prediction前的資料的register)跟現在這個register(存speculative value的register),預測會jump後的狀況)是哪個register而已。因此整體而言少了很多沒必要的speculative資料讀寫,而且speculative的讀寫bit數也會遠比讀寫哪個register的bit數還大(畢竟register也沒幾個),能夠減少很多運算跟能源消耗。
因此用physical register renaming有點空間換取時間的想法,去除ROB,這樣就減少ROB那段的讀寫,做法就是用多個register來避免資料conflict外,還會紀錄該register上一個資料,確定沒問題才把它移除,如果有branch error再把紀錄的上個資料寫回register(復原)。
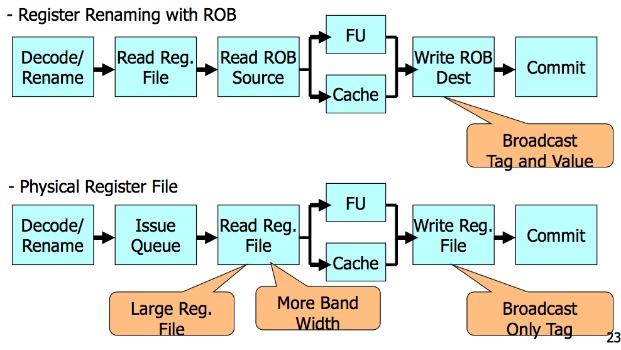
簡單而言,就是在ROB讀寫端,physical addressing只要讀寫register name(tag),但是ROB renaming要讀寫register name和對應的值,讀寫的bit數量多很多。
Physical register file
所有的實體的register
Rename Table(Register Allocate Table, RAT)
mapping,把logical register對應到physical register,如下圖F0-F7就是virtual register,P0-Pn就是physical register
Free List
紀錄哪些physical register現在是free的
ROB
多了以下欄位
- p1: 紀錄第一個physical register是不是available
- PR1: 該指令使用的第一個physical register(參數)
- p2: 紀錄第二個physical register是不是available
- PR2: 該指令使用的第二個physical register(參數)
- Rd: 使用的virtual register
- LPRd: virtual register對應的上一個physical register
- PRd: virtual register現在對應的physical register
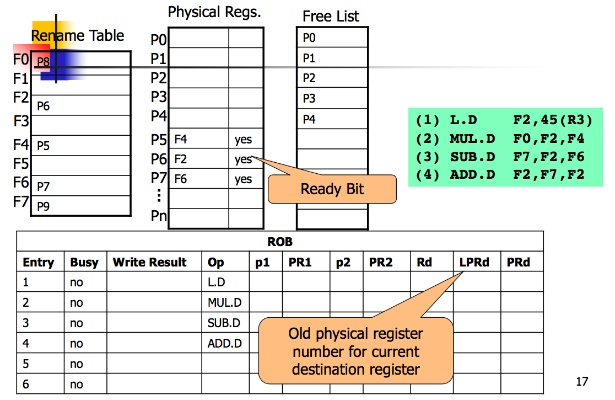
Workflow
- 當執行每個指令時,先去查看rename table有沒有對應的physical register
- 如果沒有的話就從free list抓一個physical register出來做對應
- 如果今天是要寫入的register F1,他在rename table有對應的physical register P0的話,要先把舊有P0的寫到ROB的LPRd這個欄位(等於是存舊有的mapping),在對應一個新的free list裡的physical register P2給F1,並把PRd設成P2