Virtual Memory
08 May 2019
Virtual Memory
Main memory and Disk
- 資料大部分存在disk,只有部分需要時存在Main memory,再取更少部分放置到cache,因此需要有memory跟disk的控管、對應由OS,hardware共同決定
- 從disk搬資料到memory不會像cache那麼小(一個block),而是以page為單位(因為disk到memory速度極慢,而且兩者儲存空間都不小,所以一次可以移更多資料
Virtual Memory用途
- mapping of Program address and OS memory address: 因為main memory跟disk的機制跟cache依樣。multi-tasking memory可能會滿,此時會把一些program踢出main memory丟到disk,那下次輪到此program時回來放到memory位置可能和當初的memory位置不同,所以要有virtual memory的mapping幫助程式找到對應的OS memory address。virtual address會紀錄當今對應的OS memory address。
- security issue,可以規範程式只能access依定範圍的memory, 可以達到isolation, process間不互相影響。
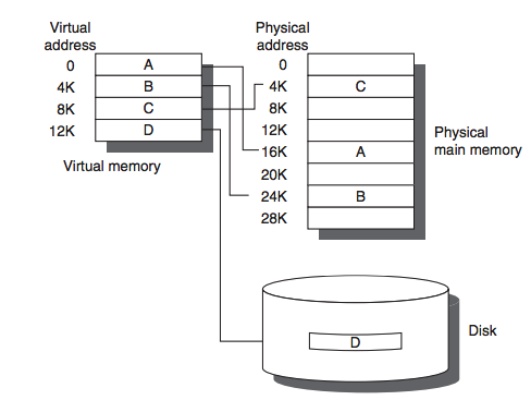
- 讓使用者看到的space比較大(virtual memory看起來範圍比實際memory範圍大,因為virtual memory有處理disk跟memory傳遞資料的機制),等於說讓有些virtual memory address對應到disk空間,virtual memory本身對應physical memory也可以是多對一,但沒有必要,後面會用page table來對應(而且是per process一個page table),所以實務上是1對1。所以可以讓virtual memory看起來比較大,當virtual memory對應的memory address不再main memory裡面,那就是page fault(memory level的cache miss), 因為要去disk讀資料, 會花很多時間就會釋放這個PROCESS的CPU資源 )
- 每個process可以有自己的mapping, 所以可以兩個不同process跑在相同虛擬記憶體的值而不會conflict, 所以process跑起來的記憶體位置由OS幫忙安排, 就算程式記憶體位置寫死也ok
Virtual page / Physical page address
page offset 使用的bit可以得知一個page多大
EX: 4K page,代表有12bits的page offset
page number長度virtual page 通常比 physical page大,所以整體而言,virtual address比physical memory address大,因此有traslation機制(translate virtual page address to physical address)
| Vritual page | Virtual page number | page offset(決定page有多大(可以容納多少byte)) |
|---|---|---|
| Physical memory | physical page number | page offset(決定page有多大(可以容納多少byte)) |
EX: 4KB pages: 則page offset 有12 bits,用12 bits來定位這個4KB pages上的任何一個點
Page Table
- virtual memory address 和 physical memory address間的translation(mapping)
- Array of page table entry
- 一個page table可以有多個pages(e.g. memory是256 bytes,但一個page只有16 bytes時, 總共就會有16個page,所以virtual address就會告訴我們要去哪個page讀資料)
- index: virtual page number, value: physical address,再加上offset就可以得到地址(offset virtual page和physical page相同)
- 每個process都會有自己的page tables,page tables會擺在main memory裡面(page table register會指向page table位置)
- page table entry也包含status bit(valid bit(reference bit), dirty bit)
- 如果virtual address指向的page不在main memory,page table entry會指向swap space(process專有,每個process都會有自己的swap space)
- 若對應的physical address不再memory,則valid bit = 0,如果在main memory,則valid bit = 1
page size
- small page size: 較少internal fragmentation, 但page table entry會很多
- Large page size: temporal locality更好, 資料相近常常被一起access, 不會因此分散在不同block, 但有internal fragmentation
現在比較偏向讓page size越大越好, 因為記憶體越來越便宜(fragmentation沒差), 而且cpu速度變快, disk速度相對慢, 一次能讀很多,就能避免cpu被disk拖累
Large page table
- 例如64 bit machines, 有64 bit address space. 這代表page table會超大,而且page table是per process.
- inverted page table: 比起用array來存page table, 改用hash table, key-value lookup(non-array),這樣就不用存整個page table, 只要存相對應的key-value pair(但這速度應該會在比array-based慢一些)
- multilevel page table:第一層page table指向第二層page table, 這樣就可以不用存一個大的page table, 除了第一層外, 第二層以後的page table可以共用
Page table replacement & writes
- associate cache方式來增進main memory運用(disk讀取速度太慢)
- 使用改良的LRU(Least recently used)來決定要把哪個memory放回disk
- reference bit為page table的status bit(相當於valid bit)
- 當memory addr被存取時,reference bit設成1,定時的把所有memory addr的reference bit變回0,當memory滿時,把reference bit為0的移掉改放新的memory block,不用counter,因為counter可能會overflow。
- 採用write-back,因為disk讀寫太慢
Page Fault handler
Page fault發生於virtual address沒有對應到的physical memory address(valid bit)或者mapping已經滿所以要找reference bit是0(LRU). 假設是記憶體已滿的狀況(要把某些physical page swap到swap或disk), 就如同Memory那張所提到的方法來進行LRU.
當MMU walks page table時, 發現那個位置valid bit是0或者process沒有權限讀那個address時會發page fault signal給CPU, hardware會把Program Counter移到Exception vectors並且把CPU mode改成system mode, 然後就交給OS的handler處理. 如果是valid bit的問題的畫, 基本上就是決定要丟掉哪個memory block回disk,讓新的block寫進memory
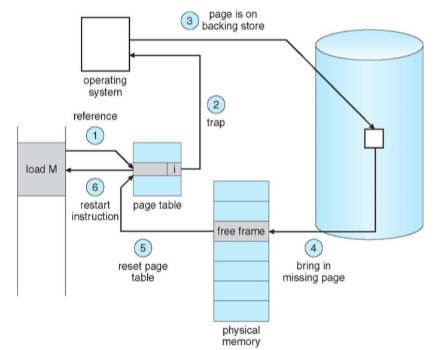
Reference: ithome page fault介紹
Second chance algorithm
上述提到做法是用一個reference bit來表示timestamp
TLB
virtual memory需要map virtual address to physicall address,需要額外memory reference,這個很浪費時間
- 需要先去讀page table看virtual address的對應,page table存在main memory,讀取也要花點時間
- 讀到physical address時,還要去access physical address(好一點在main memory,慘一點在disk )
- TLB是所有process共用,不是一個process一個
- TLB每次context switch都會清空(因為每個process的virtual address都不同), 或者tlb多一個欄位紀錄pid, 這個entry是來自哪個Process ID
- dirty bits來取代page table的dirty bits(因為memory access速度慢),不然就要變成每次有改physical address內部值都要回去page table寫dirty bits(但memory access太久)
Access Page table Entry也有 temporal locality的現象,如現在讀PTE的某個entry,附近周圍幾個entry也很有可能在短時間內被讀到。Spatial locality狀況還好,因為一個page就已經夠大了。
因此我們再加一個cache TLB(Translation look-aside buffer)存最近被access到的PTE entry存到TLB這個cache(Buffer)。這樣我們access virtual address時可以先去看TLB看看Entry有沒有存在裡面,有的話就可以少一次memory address(不用去main memory access PTE)。
通常會存16-512個PTE entry,依樣有valid,dirty bits之類的,寫回main memory(PTE)的機制. 另外TLB是所有process共用, 所以當context switch時, TLB資料會都被清空換成另一個process的TLB
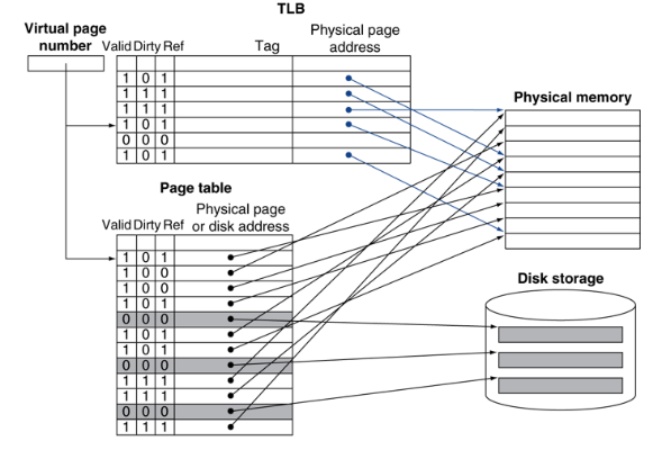
- valid bit: 該TLB entry是否有存資料
- reference bit: 該entry是否最近有被存取(用於demanding page, LRU)
- Dirty bit: 該entry的data是否有被修改過
TLB miss
去讀PTE,把該physical address讀出來,並把physical address寫進TLB
如果physical address在disk,那也會把他先搬到main memory,更新PTE,然後才寫到TLB
Virtually / physically address cache
physical / virtual address在cache上的整合
Physically addressed cache
cache紀錄用physical address,這樣在用virtual address時要先去TLB找對應的physical address再去檢查cache裡有沒有
Virtually addressed cache
用virtual address index cache,就不用TLB access,直接比對virtual address有沒有在cache裡。
缺點: Aliasing: 在multi task中,兩個process可能會共用physical address,但對應到兩個process不同的virtual address,導致TLB紀錄會變成兩筆: 兩個process各自的virtual address對應到同個data。當process A修改該data時,process B沒辦法得到shared data,因為他有cache住,在cache中有另一比entry為他的virtual address對應到舊資料,不會去讀到process A的新值。
以下為virtually address cache示意圖(cache內部狀況) 如圖,因為兩process的virtual address不同,但都對應到相同physical addr(0xdeadbeef),所以cache內變成兩筆記錄。原本0xdeadbeef值為3,process A把它改成5,但只改到自己的cache entry。process B access時,仍access到舊的值,不會收到5。
| Process | virtual address | data / physical addr |
|---|---|---|
| Process A | 0x1234 | 3 -> 5 / 0xdeadbeef |
| Process B | 0xabcd | 3 / 0xdeadbeef |
複習
index: 在cache中,決定這塊資料寫進哪個cache block
tag: 因為memory cache是多對一,所以同個index有多個memory block可能寫入,用tag紀錄是哪個memory block
memory address為tag + index + offset
Conclusion
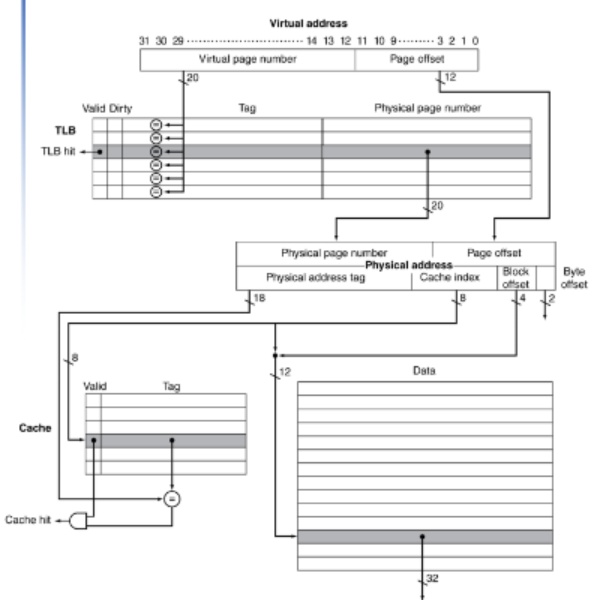
virtual address記憶體存取狀況
offset不用去TLB,offset virtual address跟physical address相同
此為physically cached,步驟:
- 先去TLB做address轉換,如果TLB miss就會去page table取physical address,如果TLB有就不用去page table了
- 去cache看該physical address在不在cache內(檢查index/tag)
- access cache data or memory data
資料不可能在cache但不在memory
Block placement
- Direct mapped
- n-way set associative
- full associative
越高associativity可以減少miss rate,但compare的cost越貴,等於同個index有存很多block,要查在這index內每個block的physical address index/tag
Replacement (for cache)
- LRU(least recently used)
- random(隨機踢出cache)
- Virtual memory(LRU with periodic reset)
Write policy
- write-through:每次修改都寫回memory
- write-back:被踢出cache才寫回memory
- write-buffer: 看時機寫出去
Source of miss
- Compulsory miss: 剛開始沒有cache(valid bit = 0)
- Capacity miss: cache滿了
- Conflict miss: non fully associate時,index有其他block了
Memory Thrashing
因為demand paging的機制, 我們在mapping時只把會用到的記憶體部分map到physical address, 其餘不分先不map或map到disk. 再根據90/10法則, 相同的記憶體可以容納下很多的process.
Thrashing: 上述狀況, 當我們真的同時有太多process的時候就會發生page fault移出的page block只能是常access的page block(因為太多process,每個memory block都很常被使用), 這種over-commited. 所以process大部分的時間都拿來處理page fault做disk io而不是process本身
解法
- 設定process數目的上限
- 保證每個process能夠得到足夠的memory避免thrashing
Global replacement
把整個physical memory當做一個pool, 然後對整個physical memory space做LRU, 缺點是thrashing機率會較高(假設process記憶體用量都超大, 每次context switch基本上就會把上個process用到的memory swap掉)
Per-process replacement
設定每個process的frame數目, 而且限定process數目上限, 缺點是如何設計frame數目不容易, 可能給過多或過少, 要根據process大小(memory allocate狀況)決定frame數目, 但這樣當然是猜測, 沒那麼優的作法(例如一個process allocate超大記憶體但只存取一小部分, 其他都閒置)
Match Working Set
跟隨90/10法則, 對於常需要讀寫的資料量來allocate frame數量. 給予讓process順利運行需要的frame數量. 基本上是看一個process他每T msec使用的page數量來決定. T msec的決定是根據page fault所花的時間來決定, 基本上就是設定一個T使我們能夠給予的frame數量造成夠少的page fault. T設定太小就沒辦法解決page fault的問題, 太小就會造成allocate過量的frame給process.
決定working set也會遇到跟LRU一樣的問題, 要統計T秒內使用的page reference的問題要用set去存, 很仔細的去track很花資源也不值得. 所以可能每次只採樣1000個memory request來判斷.
Page Fault Frequency Scheme
track proces page fault 狀況, 設定threshold來加減allocate的physical frames, 目標是system-wide的兩個page fault之間的間隔等於處理page fault的時間. Overhead就是page fault時要再做一個counter紀錄page fault的數目, 除此之外不用再特別記錄其他東西.
Kernel Memory Allocators
Allocate memory給kernel存PCB, page table之類的才能做context switch跟scheduling. kernel本身就是做memory paging的, 所以kernel本身memory access機制就不會是paging(雞生蛋蛋生雞).
Buddy allocator
allocate memory in size of 2^n(像C++的vector那樣) 這樣會有很多internal fragmentation
Slab allocator
- 根據Object type allocate memory 叫slab
- 以slab為單位allocate資料, 然後也比較容易allocate, deallocate