Memory Introduction
09 May 2019
記憶體
- ROM: Read Only,存取速度慢,但斷電資料還在,後來EPRROM是可以讀寫,但很麻煩,而且寫的速度慢
- RAM: 可讀寫,速度較快,但斷電資料消失
- SRAM: 存取速度最快的RAM,但超貴
- DRAM: 存取速度慢點的RAM,但比較便宜
- SDRAM: 主要用於嵌入式
- Flash: 結合ROM,RAM特性,可以讀寫,斷電又不會遺失資料
- Nor Flash: 跟sram依樣,能夠直接執行存在NorFlash上面的程式
- Nand Flash:沒有random access,所以一次就是取一個大block(512 bytes)下來,適合大資料的存取,很適合那種一次要取多筆資料的應用
Principle of Locality
跑程式時,data的存取特性
- temporal locality: 現在被access到的data,不久未來有很高機率還會被access到(ex: for loop)
- Spatial locality: 被access到的data周圍data很有機率被access(ex: array)
因此抓資料時,不會只抓一點,一次會抓一個block來符合spatial locality,然後存在cache來符合temporal locality
Memory hirearchy
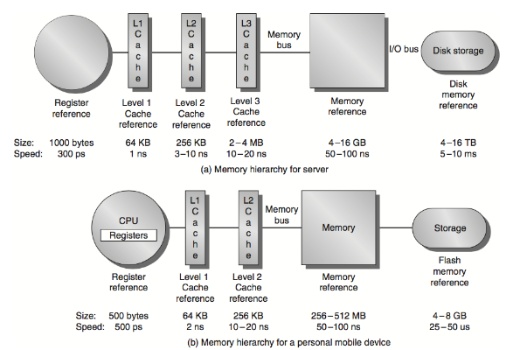
基本概念
因為記憶體要求讀取快速的話,價格非常昂貴,而讀取速度較慢的記憶體價格較便宜(例如傳統hdd用機械式讀取資料速度就很慢, 很少bps),但會有效能問題。
為了達到最高CP值Memory會分層,越靠近CPU的記憶體價格越高,儲存空間小但快(如register / cache),越遠離的則越便宜,儲存空間越大但慢(硬碟 / main memory)
基本上Memory和DiskIO都要透過bus的形式傳送給CPU
Main memory
word: 32 bits
- 資料平時都存在這,只有要用時才會把資料丟進register(register太小)。
- memory是byte-address(address為32-bits的字串)
- words在memory裡面是align
Program & Memory
我們寫好的程式執行時, OS會分配好一個Main memory上區塊然後把程式load進memory, 然後程式會去找這段memory的執行區段(text section)去執行程式(透過rip,eip來決定現在要執行哪行machine code)
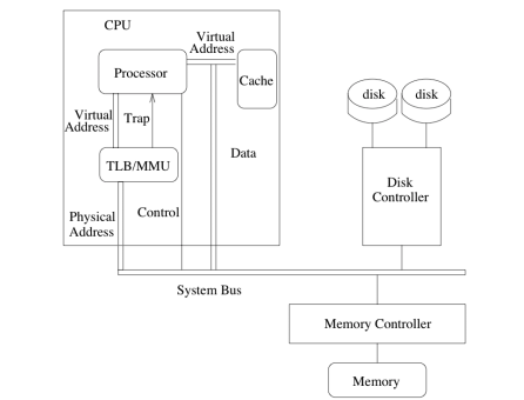
執行的程式並不會看到physical memory address,而是OS會有一個virtual memory跟Physical memory的mapping關係, 程式只能看到virtual memory address, OS會再透過mapping方式去physical address讀取資料. 一來為了資安問題避免程式看到physical addreses去修改不該修改的地方, 二來也能讓多個程式在同塊記憶體區段中執行, 達到multiprogram share memory的形式, 而不會去因為執行時影響到彼此(就算兩個程式的virtual address一樣, map到的segment,physical address也不會相同, 所以兩個程式不會有機會互相改寫另一個人的記憶體位置的值)
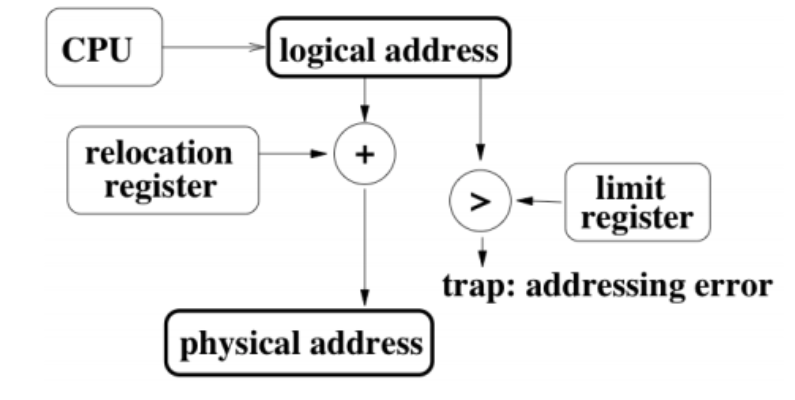
Dynamic relocation
當程式load進memory時, 會利用dynamic relocation把virtual address map進physical memory address的方法. hardware會把virtual address 加上relocation address 就會是physical address(某種平移的感覺). 然後基本上hardware還會檢查他算出來的physical address在不在OS allocate給這程式的memory segment裡, 如果不在會跳exception(因此就算找到程式漏洞可以任意讀寫, 基本上還是在程式內, 不能夠改寫其他程式的記憶體位置的值)
- 優點
- 每次跑此程式, 可以依據hardware或OS決定的relocation address的值平移到不同的physical address, 不會每次執行起來都map到同塊physical address. 甚至在runtime都可以臨時改變map到的記憶體位置(先把程式複製一份到新的physical address, 在改變relocation address的值, 這樣做mapping就可以map到新的位址, even in run-time)
- 就算program變大,大到原本OS assign的memory segment, OS可以在程式run-time移到另一個更大的physical memory segment, 只要改變relocation address的值即可成功改變記憶體virtual/physical memory mapping
- 缺點
- 程式執行在自己的memory segment, 不能share data(除非用vmmap,IPC之類的方式)
- memory運算變複雜, 變成有mapping, hardware也要額外做運算來找對應的physical address
- 記憶體大小決定了可以multiprogram的數量
Memory allocation Policy
當要把程式load進main memory時, 有這幾種不同的方法
- first fit: 找memory segment最先(早)大小比程式大的區塊, 一找到我們就選擇這個區域放我們的程式
- Best fit: 找physical memory segment比程式大的區塊中, 最小的那個, 空間最佳利用
- Worst fit: 找physical memory segment比程式大的區塊中, 最大的那個, 通常會這樣做就是考量到程式會變大, 避免超出現有的memory segment而要做很浪費時間的physical address搬移
Memory Fregmentation
我們的main memory每次會找一個連續的記憶體空間來放程式,用完就free掉, 問題點是每個程式執行時間不同, 所以原本main memory的記憶體分配是連續, 沒有空位的, 但因為有些程式結束或新的程式進來, 導致記憶體空間變得很支離破碎, 空閑的空間夠, 但是單一個小的空閑空間不足以塞下要放的程式
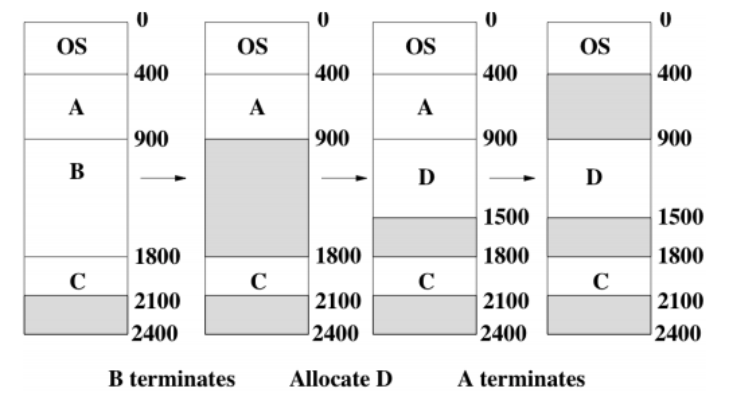
- External Fragmentation: 就如上述OS的狀況,不斷的load程式跟close程式導致記憶體變的破碎
- Internal Fragmentation: 發生在假設physical memory segment大小只比程式要求大一點點時, OS會直接把整塊給程式, 就不管多allocate的那一點點
Compaction
解決fragmentation的一種方式, 基本上就是暴力把所有程式都重新移到最上面,下個程式的記憶體區段位址接上個程式的記憶體區段位址的尾巴, 所以就是把所有program都移動他的memory segment, 把空間全部擠出來成一大塊空閑的memory segment
Swapping
不用所有程式都存在Main memory, 只有在跑的那幾個在Main memory就好, 其他在Disk, 所以當發生context switch時, 就把沒有要執行的program把他放回disk, 把要執行的程式load到memory
Memory Paging
上述swapping, compaction都太花時間, 因此OS用memory paging來解決fragmentation的問題, 同時這個做法也能有更高concurrency
90/10法則: process花9成的時間access他擁有的10%的memory. 因此, 我們只需要把部分程式load進記憶體, 其餘部分放到disk, 要用到再load進來, 這樣可以更有效率使用記憶體, 相同記憶體容納更多process
因此我們把process變成fix size pages,然後把這些pages放到main memory裡,因此每個physical block都是以page為單位(a.k.a Frame)
這樣可以解決external fragmentation, 但還是有internal fragmentation(因為我們要把程式的memory切成以page為單位)
如圖, 我們把一個程式的記憶體拆成6 pages, 把他分別對應到physical memory不同的地方(page也可以對應到disk, 不一定要在main memory), 此時會需要一個page table來做logical address跟physical address的翻譯。
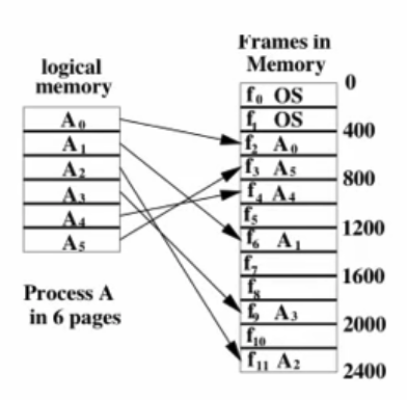
只是這種方式, 因為程式的memory到physical memory已經不是連續了, 所以不能單純用來做某種平移, 必須要用page table來找到virtual address跟對應的phyisical address, 而page table是per-process的。 詳情可以見virtual address的筆記
translation的機制為page table放在main memory,然後透過hardware做實際上運算
page table的優點是能夠輕易讓兩個process輕易的shared memory(讓兩個page table的entry指向同個physical page), 但通常這種shared memory都是preentrant,也就是說process使用它但不能更改裡面的值(read-only), 這樣可以省下很多空間, 如果多個process用同樣的資料, 就不用每個process複製一份, 就page table指向那個physical address即可, 只需要一份.
valid bit
page table一開始init時會預測該程式會使用到那些memory block 提前在page table做好mapping到physical memory, 其餘的valid bit設成0(代表該mapping還未建立), 當發生這樣狀況時稱為page fault, 會依據下面談的機制allocate一塊physical frame然後建立新的mapping. 所以page table initialize時很多位置valid bit是0, 是透過page fault才慢慢地allocate physical frame和增加page table entry.
Swap
基本上是disk,存取速度很慢,目的在於減緩memory,RAM的pressure,或者應付緊急狀況用。或者可以當成介於Memory跟disk中間的一層level cache。
通常paging時被踢出的memory block或disk block會先存在這裡. 當RAM的壓力過大(usage rate太高),此時就會用到swap來舒緩RAM的壓力。通常用到swap時,程式速度會變超級慢。因此他可以某種程度的避免程式因為記憶體用盡所以crash,他能夠讓即使記憶體不足情況下還是能夠讓程式能執行一陣子,能夠給系統管理員更多發現問題的時間,或者給予程式更長執行時間,讓他能完成重要讀寫。
Reference
Memory access Workflow
- Process request k memory pages
- OS allocate k pages給process, 然後把這k pages放進page table(logical address跟physical address對照表)
- OS把TLB(register-level page table, 下一章節介紹),的valid bit設成0(flsuh掉TLB, 因為是大家共用)
- OS開始跑process, 隨著程式存取記憶體, TLB也順便更新
PCB內容
- 包含page table和TLB
- 當發生context switch時, 把page table register value(regiser值指向page table再memory的位址), TLB copy到pcb, 然後flush TLB, 讀進下個要執行的process的PCB, 把資料填上
Direct Mapped Cache (Cache的機制)
因為cache的大小遠比memory還小,所以對於怎麼存資料、釋放空間有一套方法來決定資料何時要放在cache,何時要踢掉
memory address名稱(共32bits),每次access memory是搬一個block,block大小由OS定義
tag + index為一個block, offset表示block內有幾個word
index: 來決定要對應到哪個cache
tag: 可以說明該次的cache是由哪個tag的memory address提供的
Offset B.O: word裡面的第幾個byte(一個word 4個byte)
Offset W.O: word offset(cache裡面的第幾個word)
| tag | index | offset(W.O,B.O) |
|---|---|---|
memory address naming
假設一個memory address有32bits,offset佔 5 bits(W.O 3 bits(代表一個block有8個words),B.O為2,一個word 2byte),index佔3個bits(取決於cache大小),剩下都是tag的bits
mechanism
Memory address對cache的對應是多對一,所以會有多個memory address對應到一個cache address,所以cache address只會放那幾個對應的memory address傳上來的值 所以假設很衰存取的幾個data的memory address剛好都是對應到一個cache address,那cache一直清掉重寫,一直cache miss
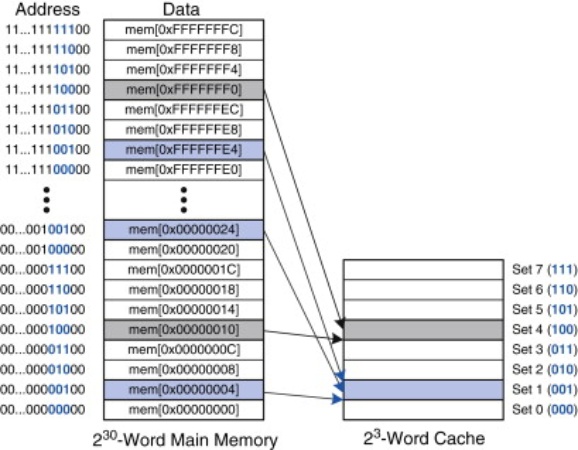
Valid bits and tags(cache address naming)
由tags可以知道存在cache裡的資料來源是哪個memory address(tag + 該cache的index
Valid bits: 表示該cache現在裡面有沒有資料
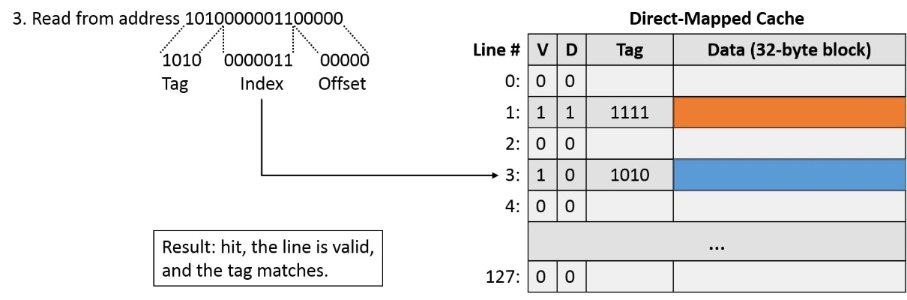
Example 1
假設32-bit address(memory address的描述為32 - bit,cache可以用更少bit描述address),directed map cache,
\(2^n\) blocks
\(2^m\) block data size words
index = n bits 代表總共有m+2個bits的offset(m個words + 2個bits)
Tag size = 32 - (n+m+2)
Number of bits : block*(memory address佔用的bits + data佔用的bits)
\(2^n (2^m*32+(32-n-m-2)+1))\)
Example 2
16KB data, 4-word blocks
1個word 4個byte,16KB data總共有4K個word
因此總共有1024個blocks(index)
cache size = block number * (memory address用bits + data)
cache address總共有18KB(原本data + cache memory address)
Example 3

Cache Block size consideration
block越大能存的data越多,越能發揮spatial locality,所以cache miss會減少。
缺點:
- 但相對cache size固定,導致block number變少,變成更多對一,另一方面更容易cache miss,
- block size太大會抓太多資料,很多可能都沒用到(pollution),且cache miss的資料讀寫overhead變大(要讀寫更多byte, 因block size變大)
Cache/Memory sync 機制
WriteThrough
保持cache,memory資料一致性,因為資料是從memory讀到cache,CPU取cache資料進行運算後,得到新的值寫回cache/register,這時不代表memory資料也update了。因此要有機制把cache資料寫回memory,確保memory的資料也有被更新。
把資料寫道cache時也一起寫到memory或disk, 好處是比較不會有data loss, 如果電腦突然power off, RAM資料會消失。
缺點是耗時,寫cache時同時也要寫memory,會導致很多CPU cycle浪費
WriteBack
永遠只寫到cache,只有當block被踢出cache時(cache miss被overwrite)時,才會寫回memory(利用dirty bits來表示cache block有沒有被改過)
WriteBuffer
介於上述兩者之間,先把資料寫到cache / memory之間的buffer,從Buffer寫到memory寫完後才會把buffer清空。 慢的點為Buffer寫到memory,CPU平時不用等可以做自己的事,Buffer可以趁空擋寫到memory。只有當Buffer滿時,CPU才要halt, 等Buffer有空位才能把資料寫到Buffer再繼續進行。
Write allocation
Write around
直接寫進memory,不特別讀到cache(某些資料他可能久久只存取一次,此時沒必要放到cache,直接對memory做讀寫,ex: init, memset)
Write-back
先讀到cache,從memory fetch block
Main memory to Cache
Memory(Dram)透過bus把資料送到cache,有clock bus,比CPU clocktime慢,所以傳送速度慢,
cache block read
把資料從Main memory需要的步驟及時間
- 1 bus cycle for address transfer(傳address告訴main memory要讀哪塊資料)
- 15 bus cycle for DRAM access(DRAM讀取資料1word所需時間)
- 1 bus cycle per data transfer(1次傳1個word給cache縮需時間)
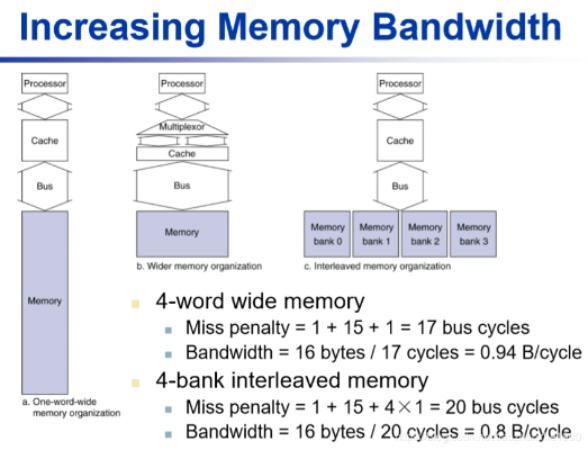
EX: 4-word block 1-word wide DRAM
Miss Pnealty = 1 + 15*4 + 4 * 1 = 65 bus cycle
所以一個Cache miss要把資料從memory寫到cache所需時間蠻多的
Bandwidth 16 / 65 ( Bytes/cycle)
其中2,3點可以做優化
第2點:
DRAM一次讀多個word時,可以把memory分成多個bank,不同word在不同的bank,那4個word讀取時可以同步,就不用sequential,花費時間=1個word,但還是要sequential透過bus傳給cache
第3點:
當然bus越多(4-word wide…)傳送速度會快更多
Cache performance measuring
Memory stall cycle(cache miss)
= \(\frac{Memory Access}{Program}\) * Miss rate * Miss penalty
= \(\frac{instructions}{program} * \frac{Miss}{instructions}\) * miss penalty
cache miss 有分data cache miss 或 instruction cache miss,data cache miss不一定會寫到cache,可能直接在memory操作
Memory stall一直是一個問題,即使現在CPU clock time越來越低,CPI越來越低,但是memory不便會拖慢速度,cache miss影響很顯著,消耗的clock cycle更多。
Average memory access time(AMAT)
AMAT = Hit time + Miss rate * Miss penalty
Associative Cache
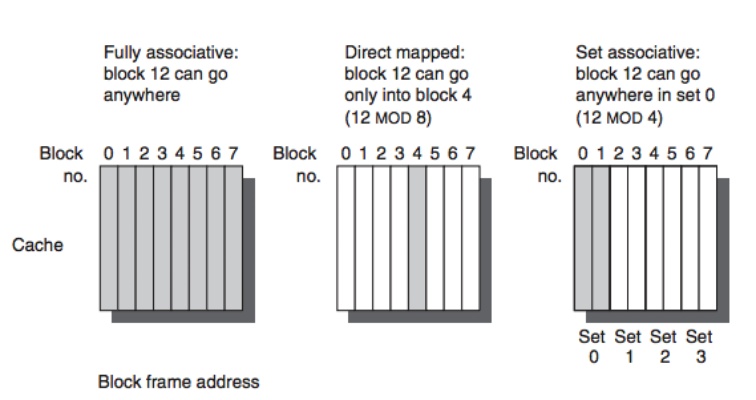
n-way associative
- Memory寫到cache,他有複數個選擇,不是多對一,而是多對多,他可以選擇寫到數個cache blocks(看哪個是空的)
- 檢查n個entries就好
- 但是cache可能沒辦法100%的block都剛好用到,因為data只能被歸類在特定的幾個block,不是有空位就放
Fully associative
- 只要cache有位置,Memory就可以寫進去,Memory block跟cache block沒有對應的關係
- 每次找cache資料時,要每個entry都比對才知道資料在不在cache
- cache能完整使用,100%使用,只要有空位就放,所以不會有某些index的data特別多導致miss rate很多
Replacement Policy
從memory fetch一個新data,如果cache可以填的block滿了,就要把一個資料從cache剔除,才能把新的資料從memory寫進cache
Directed Map
沒選擇,因為是多對一,所以只有一個cache block,有cache miss(要其他tag的memory addr),就只能把原有寫回memory,新的寫進cache
Leat-Recently used(LRU)
如果是associative cache,選最少用的(最久沒用的)寫回memory,空出空間給新的block
實際上實作不會存整個timestamp或一些非常方便的Data Structure, 會占用一些空間,TLB跟page table空間珍貴, Data structure則是雖然可能能夠幫助我們很快速查找block或者iterate, 缺點是要存data structure就要存在Main memory, 所以絕對不會比較方便. 而我們也不需要真的到非常精確能夠排序出page table entry access的順序, 只要大概知道那些最近被access, 哪些沒有.
所以只會用1-2個bit來代表timestamp, 如果有被access就把MSB設成1, 每一段時間就把所有TLB的entry timestamp右移, 這樣就可以作為LRU用, 只比較兩個bit, 一來空間不會占用太大, 二來可以直接交給hardware處理. 但這樣的問題就是 實際上還是需要iterate整個TLB才能得知哪個timestamp最小.
具體做法是, Page table是一個circular linked-list, 所以就iterate整個Page table, 原本是1的block把她的reference bit改成0, 找到第一個reference bit是0的block把資料放進來,然後reference bit設成1, 然後下次page fault再從這裡繼續iterate.
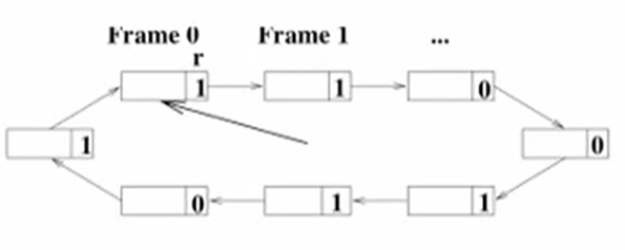
Enhanced Second Chance algorithm (reference + dirty bit)
Page fault的成本是, 每次都要把原本在Memory的那個block寫回disk, 然後再從disk把要求的那塊寫進memory. 但如果本身有些Memory block在access時沒被改動, 是可以optimize的, 可以不用把memory寫回disk這個IO部分,只需要把disk上要求的資料覆寫現在在該memory的block. 而判斷資料有沒有改過就是用dirty bit來判斷. 所以page fault要達到更高準確率跟效率, 就要同時看dirty bit跟reference bit, 不能只看單個, 舉例來說 如果兩個bit都是1, 代表他可能近期還會再被存取, 不要選這個, 反觀如果兩個bit都是0 就代表沒改過而且很久沒使用這個block, 就選這個.
選擇的方法可以是每次iterate page table這個circular linked list, 另(r,m)代表reference bit, dirty bit. 如果兩者都是1, 就先把reference bit設成0, 如果是(0,1), 就把資料寫回disk, 然後變成(0,0). 持續iterate直到找到(0,0).因為每次iterate都會至少把page flag的一個1設成0, worst case是第三輪一定會找到至少一個(0,0)的page block.
Multi-level Cache
CPU -> Primary cache -> L2 cache -> L1 cache -> Main memory
越接近CPU越快、儲存空間越小,相反越慢、儲存空間越大
Primary cache: optimize hit time。
L2 cache: 很怕miss,要optimize miss rate,因為一但miss,就要去memory,這部分的latency超大,所以要極力避免miss rate
miss rate根據memory arrangement pattern有關,和compiler, algorithm behavior之類的有關