CPU Architecture
10 May 2019
CPU Overview
Terminology
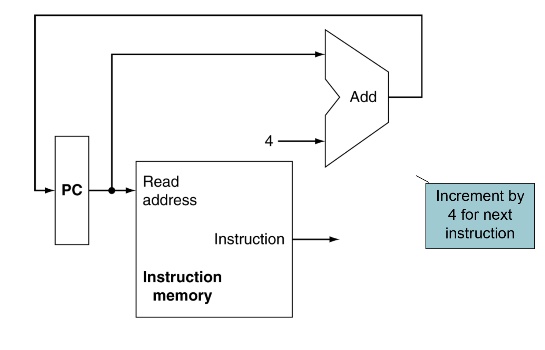
- PC: program counter,指向當前要執行的instruction,每執行一個指令PC + 4(利用adder)
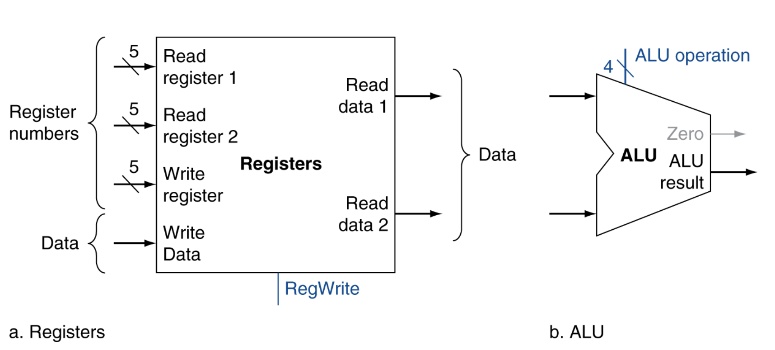
- Register number:就是register
- ALU: 運算單元(加減乘除..,計算memory address)
- contro unit:因為整張流程圖有很多地方是不同線路交錯,也就是會有不同運算結果走同條線路,此時就要用multiplexer來決定要讓哪個值通過,例如PC可能傳回來的值是PC+4或者jmp後的address,此時就要用multiplexer決定要讓哪個值過,最後是PC該有的值。而control unit就是控制multiplexer的內容,control unit接收instruction as input,然後把結果傳給各個multiplexer告訴他們該讓哪個值過,其中也包括規範register/memory是write enable還是非write enable
- Datapath: 一個MIPS instruction他在CPU裡資料走的路線
Logic design
- low voltage: 0
- high voltage: 1
- one wire per bit
- multi-bit data可以用multi-wire buses
- 1個ALU可以處理1個bit,所以要處理32bit data,要同時有32個ALU,然後32 bus處理
- 一般硬體有clock cycle,一個clock cycle能對register或memory做一次讀跟一次寫,所以要連續讀兩次就要兩個clock cycle
- clock有up,down,只有在clock從低變高或高變低才能執行寫入,如果又有write enable flag,則要同時有clock值變化且write enable要on,這兩條件符合才寫入
CPU Overview
一個clock cycle,memory只能read一次write一次
Instruction Fetch
Instruction獨立自己一個memory,跟data memory是分開的
R-Format Instruction
input有三個register,有兩個是input運算用,另一個是output address,就是最後算完要write reg時會把data寫到這個reg。
regWrite決定register是不是write enalbe(依據instruction有沒有要寫道register決定)
Total Workflow
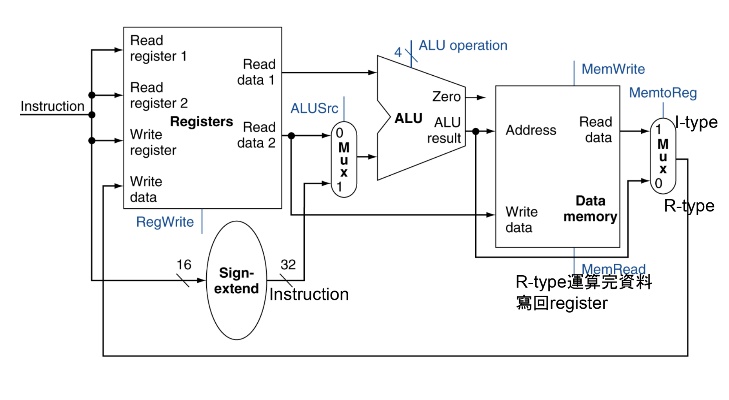
Load/Store Memory Instructions
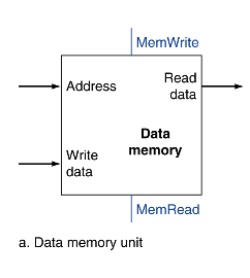
有memory write-enable, read enable flag,確保不會在不該讀的時候讀memory,不該寫的時候寫進memory
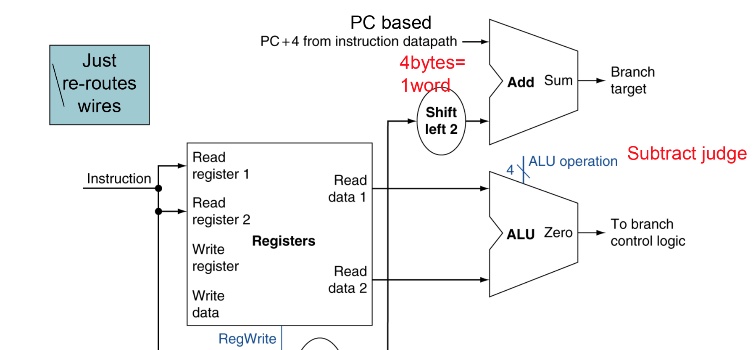
Branch
ALU進行cmp運算,兩值相減看是否為0,zeroflag傳給branch control logic,看要給PC + 4過還是adder算得新的address過
Full Datapath
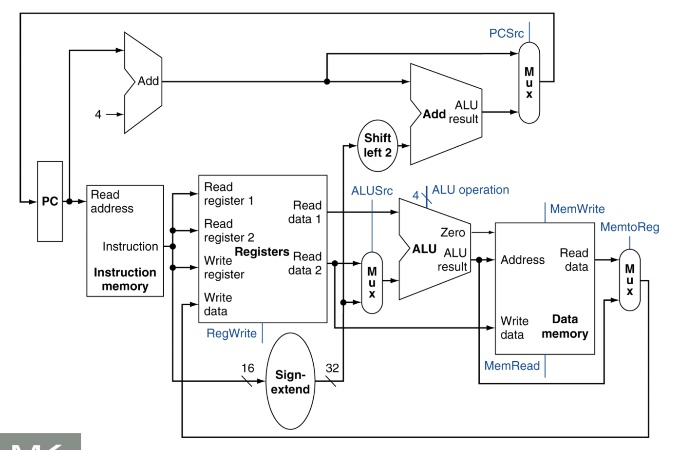
只要路線有由右往左寫的path就會有Hazard的發生,例如最後寫回Register
Control
讀取instruction,送出signal給register, memory, ALU告訴他們應該要有的設定(EX: write enable, read enable, ALU operation, branch flag, ALU input source(memory or reg))
基本上只要讀取opcode大部分指令都可以決定,讀取opcode,就可以知道register, memory設定,只有是R-type的Instruction時,
ALU Control(second-level control unit)
不是所有情況都會用到。只有是R-format,要根據funct field的值來決定ALU要做的operation時才會用到。
input control的signal + instruction,funct部分,產生對應的ALU OPcode signal(intermediate),給ALU,告訴他是要執行ALU operation中的哪種運算(加減乘除)
因為R-format還有funct這個field來決定要執行加減乘除,此時才會需要把funct的值一起input進來control產生signal。
Clock time
電腦本身是一個sequential circuit, 而為了讓整個pipeline運作以及CPU與其他硬體間的傳輸順利所以會特別訂定clock time, clock cycle來同步這些task之間的溝通. 此外也能透過這些值去測量程式執行所花的時間
CPU Time = CPU Clock Cycles * Clock Cycle Time = CPU Clock Cycles / Clock Rate
Clock Rate其實就是CPU頻率
Clock cycles就是 Clock tick, CPU電晶體震動的週期,基本上就是每個tick就是一個CPU cycle(電晶體震動一次),代表CPU處理一個unit task的單位. 每個clock cycle大小固定(就是CPU tick一次需要的時間), 但每個指令執行需要的clock cycle數不同, 例如乘法比家法複雜, memory load比cpu運算的指令還要更多時間, 又如cisc架構下每個指令執行的cycle數也不同. 因此程式很多的time相關的運算就是紀錄在CPU的timer tick幾次後會發interrupt給CPU叫他執行某個task這樣
因此對於一個程式我們想要提升它的效能 我們有幾種方法
- 減少Clock Cycles
- 提升Clock Rate
更具體而言,要更動這兩項變因有幾種方法
- 硬體的規格(記憶體讀取速度, CPU頻率, Instruction set的複雜程度)
- Compiler的強度(是否能產出有效率的machine code, 避免使用要花很多時間的instruction)
- OS scheduler的實作(能夠分配多少時間給process, 是否能有效率分配資源, 在使用硬體,lock之類的狀況下仍能做好scheduling)
- 開發者的開發程式能力(演算法, system call使用之類的)
軟體上我們除了單純的CPU Time來測量程式執行效能外, 還有分期他幾種方式
- CPU Time: 總共的程式執行時間
- User Time: Process在user mode下執行的時間
- System Time: Process在kernel mode下執行的時間
- Idle Time: CPU並沒有在使用的時間(例如Process在acquire sleeping lock或者做Hardware/IO處理之類的)
會定義以上的其餘時間就是想更清楚知道程式執行的bottleneck在哪塊, 而程式的效能除了跟程式邏輯有關外, 也跟OS kernel scheduler的實作有關. 原因是在軟體執行跟硬體執行時,為了追求效能要優化的地方不同. 硬體執行優化是希望能夠減少latency(很快發出request,很快得到結果), 而CPU執行的優化是要增加throughput(每秒能執行的指令數增加), 因此要看scheduler是偏向哪種模式. 具體而言, 增加CPU的效能或者變更多核會增加throughput但不會減少latency. Linux kernel是偏向硬體執行優化, 減少latency的部分, 原因當然是希望給使用者更好的體驗, 那當然throughput方面就沒辦法最佳化, 但當然差距可能也不是那麼大.
Cycle(Clock) time
用longest delay來決定: 最重的為load instruction
Load Instruction datapth: Instruction Memory - > register read -> ALU -> write memory -> write register ,最長的datapath,大部分R-format可以少掉memory read/write這段
Pipeline
讓多個instruction能夠執行,不是等一個instruction執行完才換下一個。 因為在執行ID時,下一個指令就可以開始IF了,所以速度變快。
指令的stage:
- IF(Instruction Fetch)
- Instruction fetch from memory
- ID
- Instruction decode & register read
- 對MIPS,RISC來講,因為instruction長的差不多,所以decode快,但像misc,instruciton decode就要比較久
- EX
- Execute operation(ALU), calculate address
- MEM
- memory access(read / write)
- WB
- write register
並不是所有指令每個stage都要執行,但load每個stage都要,所以load指令花的時間最長。
值得注意的是,可以設計成一個stage前半個clock cycle設定成write op,後半個clock cycle設定成read op。
所以同時執行ID,WB是沒關係的,因為前半段會先write,接著同個stage後半段才read
speed up = Time between instructions(non-pipline) / Number of stages
越balance的stage,speeup越多(throughput增加,同時可以有多個指令在跑)
Hazard
資源被occupied時,後面指令要wait,等到上一個指令弄完才能輪到他,導致很多clock time idle
Structure hazard
需要的resourece還在用(ALU, memory),同時兩個instruction要store / write data。
Data hazard
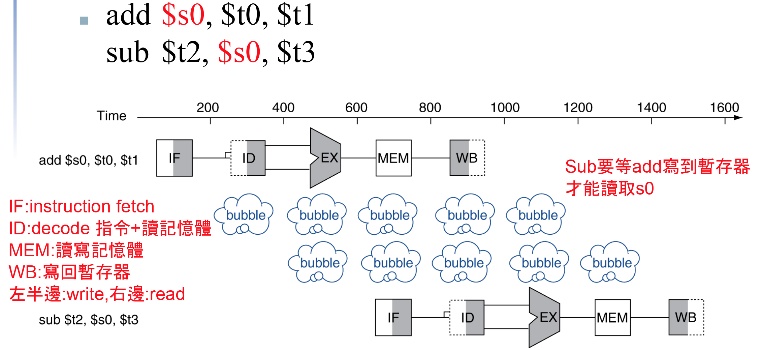
reg,memory read write,後面指令要用的data前面指令也正在用。例如上個指令還在reg write,那下個指令要等register write完才能read。不然會讀到錯誤的值。
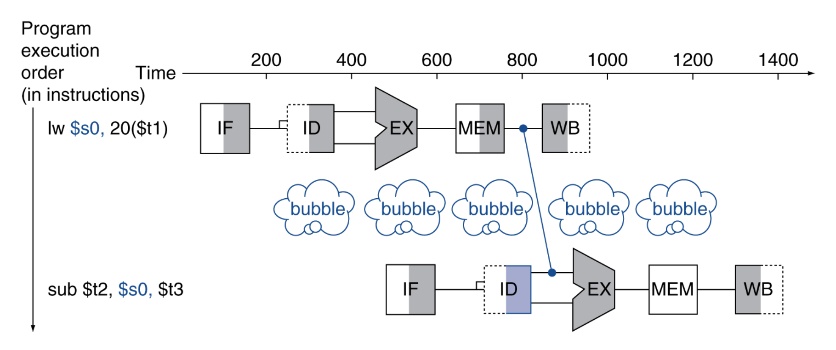
add $s0, $t0, $t1
sub $t2, $s0, $t3
add指令要先把資料寫進s0,sub才能讀取s0資料,造成bubble。
Control hazard
branch的問題,因為branch決定要不要跳要時間運算,導致PC不知道要執行哪行指令,是要jmp還是直接PC+4
Forwarding
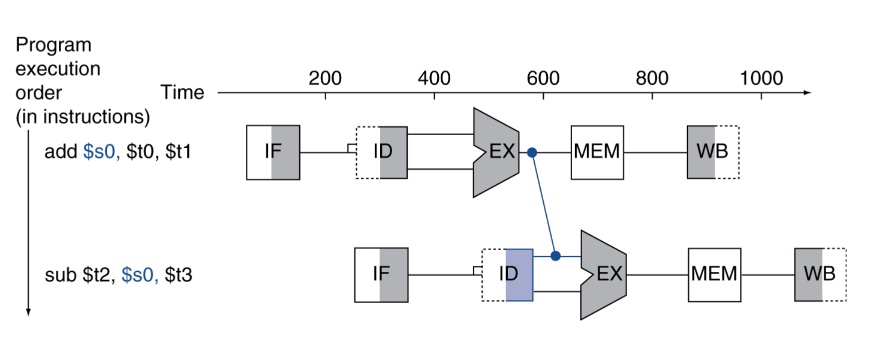
因為Data hazard,後面指令的input為前面指令的output,那其實不用等到寫道register裡面再讀。可以ALU運算完後直接傳給下一個指令當input。這樣就可以節省很多時間(不用Write register)。
舉例而言,我們可以在add ALU算完後,直接丟給sub指令的ID stage,這樣就可以少很多NOP。
add $s0, $t0, $t1
sub $t2, $s0, $t3
又或者可以從memory load以後不用寫進register直接傳給下個指令
branch也可以,直接把ALU運算完結果傳給下一個指令
Code scheduling
Instruction reorder,把data hazard, conflict的instruction拆開,中間多插入一些後面的指令,後面指令先做,如果沒影響的話
Branch prediction
Branch就算使用forwarding,還是難以避免有bubble,尤其在pipeline stage數目多時(課本只給5個),那此時就會stall很多clock cycle。所以採用branch prediction先猜測下個instruction address,就不用stall。但猜錯的話也相對有penalty,要把現在執行的指令清掉(把stage register的值清空,這樣就不會read/write到register memory),改成正確的那個,這樣結果就跟沒猜,等到結果出來再執行一樣。
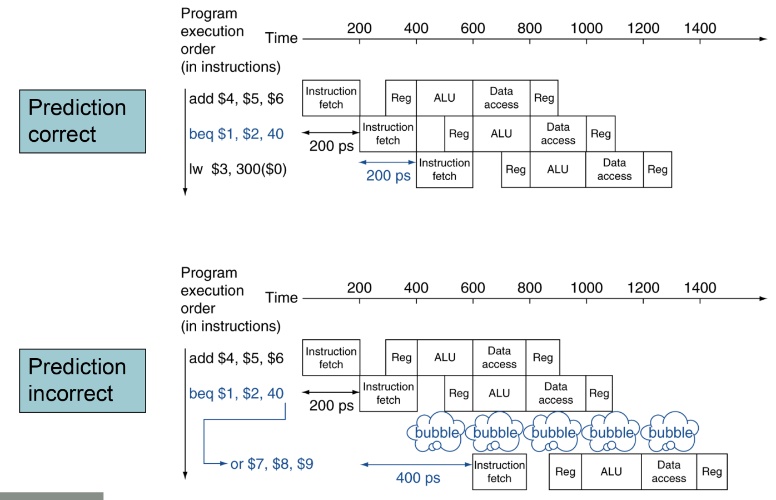
Static branch prediction
固定的猜法,不會因環境、狀況改變而猜不同值
Dynamic branch prediction
蒐集過去猜測狀況,來預測下次branch要怎麼猜
Pipeline Register
雖然有做pipeline以及一些機制防止hazard,但還是有可能會有structure hazard,同時使用同個資源,例如:
add
lw
此時執行到最後的multiplexer(srcWB),要決定是由add的值寫回register時,但此時lw因為比add晚執行ID,所以lw的op code送到control,control值被overwrite,把lw的signal傳給各個multiplexer,此時最後一個multiplexer(srcWB),被overwrite成write register的input值是memroy address而不是ALU運算結果。
發生此問題的原因在於,後執行的指令把multiplexer改成符合自己的,導致先前指令可能原本multiplexer值被蓋掉。所以在每個stage要增加一個register,先把signal halt住,避免stage的information影響到其他stage,cache住的signal跟著instruction移動到下一個stage,也傳到下一個stage register halt住。