計算機網路_CH3
26 April 2020
計算機網路_CH3
網路架構:
- 分成五層,各層處理各自任務,不互相影響,例如router只萃取到Network layer資訊,他不會處理任何Transport Layer的資料
- Transport Layer把應用層的資料切成片段,每個片段加上header變成transport layer segment,再把每個segment傳到Network layer包上該層的header
- 傳送資料時,資料由上層往下層包,接收資料時,資料由下層萃取(去掉header),到應用層得到資料
- Transport Layer只存在接收、發送端,中途的router都沒有
- Transport Layer的服務受Network Layer的影響,若Network Layer沒有保證Bandwidth、最久多久能收到,那Transport Layer也無法保證多久能收到

-
舉例: 假設有A,B兩家人很愛互傳資料,A家的Andy,B家的Bill負責統一收發自己家的人的信,就是他收到信後,會拿去給自己家的收信人,送信時,會把信拿到郵局去寄、郵局會把它不斷以建築為單位傳遞
-
關係: 家人:process Andy、Bill:Transport Layer(把送到家裡的信轉發給家人) 郵局:Network Layer(把信件forward,但是是以家為單位,不是以人為單位,故單個人不會碰到信件) A,B家:Host(end system)
| Network Layer | Transport Layer |
|---|---|
| logical communication between Host | logical communication Between Process |
Transport Layer
- TCP:
- Congestion Control:避免整個網路壅塞,如果網路壅塞也會放慢封包傳送腳步
- Flow Control : 避免接收端接收太多來不及處理導致drop,TCP會放慢腳步
- Connection Setup : 要先handshake建立連結,保證對方收到
- Transport Layer未提供:
- Delay Guareatee:沒有保證多久一定收得到,可能封包傳遞繞遠路或者loop
- Bandwidth Guarantee:沒有保證頻寬最小值,所以可能頻寬很小
- TCP/UDP同時提供:
- header Integrety Checksum
- multiplex/demultiplex:像上面收發信的人,會傳給特定process或把信傳給郵局(network Layer)
Network Layer
IP:
- Best-effort Delievery service(最有效率把資料從一個host傳到另一個host)
- Unreliable Service(不保證收到封包的順序、不保證收到封包的完整性,只告訴封包傳送路徑)
Multiplexing & Demultiplexing
- Demultiplexing
接收端的transport layer把進來的資料分配到特定的socket,因為Transport Layer的data裡有一個field是存該封包要送到哪個socket,所以當Transport Layer收到封包時,檢驗這個封包的field就知道要分發到哪個socket
舉例:上述例子Andy收到很多來信,依據信上面的收件人給他的家人
- Multiplexing
發送端把所有的socket的資料(data chunks)打包好(加上那個field,之後要Demultiplexing),之後傳道Network Layer
舉例:Andy收集所有家人要寄的信、寫好個別信件的收件人,然後傳給郵局
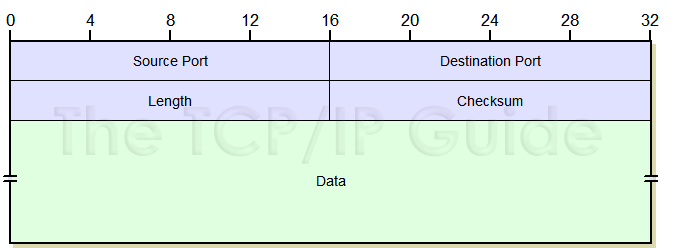
Port
上述提到封包裡有一個特定的field告訴Transport Layer要把資料傳到哪個socket, 那個field就是 Source Port number field、Destination Port number field
- 總共有16bits,0-65535個port
- 0~1023是well-known不能用(有特殊功能)

傳送方式(UDP)
Transport Layer把傳送的資料包好(依上面header格式,加上source port,Destination port)後傳到Network Layer,Network Layer把資料加上Network Layer的header,像ip之類的, 接收方收到後,Transport Layer依據封包上面的port分配到特定的socket,
傳送方式(TCP)
Client先發送connection reqeust(connect)給server,此封包訊息主要包括dst,src PORT,server accept後建立一個新的socket(依據資訊就是src,dst IP/PORT)
注意
UDP socket是依據接收端TCP/IP的方式區分,也就是說,假設兩個host(不同IP),傳送資料到同一個server的同一個Port,那這兩個資料是傳到同一個接收端的socket,所以socket不是一對一,而是可以多個user對一個socket,但TCP socket同時要看4項(src,dst的IP/PORT),所以即使不同host連到同一個server port,server會建立兩個socket處理這兩個request
| TCP | UDP |
|---|---|
| 4 tuple(同時看來源、目的的IP/PORT) | 2 tuple 只看目的地的IP/PORT |
| 不同的src IP/PORT連到同個server用不同socket | 不同的src IP/PORT連到同個server用相同socket |
| 封包會包括src/dst port number | 封包會包括src/dst port number |
Webserver and Transport Layer
原本應該是一個socket對應一個process,但是這樣webserver會很busy(尤其是Non-persistent),傳送一個網頁就要連線很多次,因此現在改成很多socket連到同一個process(只有一個process),這個process再開thread來個別處理
UDP
- Connectionless : No handshaking
- 提供簡單的checksum、multiplexing/demux
- 過程:
- UDP layer把應用層資料加上src,dst PORT後傳到network Layer
- Network Layer加上IP等資訊傳到接收端host
- 接收端萃取根據dst PORT開一個socket
- 實例:DNS,multimedia(講求速度,可接受data loss)
- 優點:
- 適合realtime service,TCP要包更多東西,還有congestion control會放慢傳送速度
- 不用handshake,TCP要三次handshake,非常花時間
- 不用維護連結,因為connectionless,不用像TCP要在意receive,send buffer,congestion control,ack parameter….
- 有較小的header,所以相同的資料量,UDP傳送的overhead較小
- 缺點:
- 較高機會Data Loss
- 格式:
- Length : 封包大小(UDP封包大小不固定)
- CheckSum:檢查封包有沒有被改過
- Check Sum作法: 把封包改成二進位全部加起來,overflow的話改用1’s complement(0->1 1->0) 最後結果在接收端把checksum和前面的所有二進位值加起來,最後結果應該要得到全部都是1
- Why checksum:
- 傳送過程中有些Layer可能沒有checksum
- 可能是從link layer在傳過來的過程中發生error
各種應用使用的transport Layer

rdt(reliable data transfer)
- Assumption :
- 資料傳送可能會package error但不會reorder,lost(後面的sequence number會出事)
- 傳送方向是一個方向,就是sender傳給receiver不是雙向

- rdt1.0:
- 假設所有傳輸都是reliable
- 下圖箭頭上面是發生的event,下面是此event對應的action

- rdt2.0:
- reason:因為資料在實體層傳輸時可能會出現bit error
- ARQ (Automatic Repeat reQuest) protocols: 收到訊息回覆positive acknoledgement,沒收到或錯誤回覆negative acknowledgement
- Receiver feedback : 接收到資料後,回傳ACK代表收到資料,NAK代表沒收到資料
- Retransmission: 如果server收到NAK就在送一次資料給client
Sender 註:sender在等待ACK,NAK回應時,不能接受上層傳下來的檔案,所以要等這個檔案傳成功才能再傳新的檔案(stop-and-wait protocols)

Receiver

- 缺點:
- 萬一ACK,NAK corrupt就完了
- 解法1:加非常多checksum讓他能自動修正
- 解法2:收到corrupt的ACK,NAK就當作NAK,但會有sequence的問題,接收方接收到sender data會不知道那是新資料還是舊資料重送,所以要用sequence number來解
- 例如:如果client傳ACK給sender但corrupt,這時sender會傳舊資料給client,但client會以為這是新資料
- rdt2.1
- 增加sequence number:前面和2.0版一樣,只是sender傳過來的值多一個sequence number,client會做state轉換,假設client傳送ACK跳到state1,但是sender收到corrupt的ACK0那他就會再傳一次資料0,此時client state和收到資料state不合,就知道ACK corrupt所以再送一次ACK0,故若收到的資料state不合,是傳sender傳來資料的state的ACK,NAK依樣只有corrupt時才傳
- 收到資料沒有corrupt但sequence不對:送前一個ACK給sender
sender

client 註:receiver收到錯誤的corrupt data就送NAK,收到錯誤順序的data但沒corrupt就送前一個收到data的ACK

- rdt2.2
- 不用NAK,錯誤data全部改送前一個收到的data的ACK
- 若收到兩個相同sequence ACK,就知道這個ACK的下一個data沒送過去
- 跟2.1差別就在於沒有NAK
- sender收到錯的都會再傳一次現在這份packet
- rdt3.0
- deal with packet loss
- 解法:自己定義一段時間,時間到,不管對方有沒有收到,sender再傳一次(若以等待時間夠長在做重送的動作,一來不好預測時間、二來效率低)
- 產生問題:duplicate data packet
- 解決方法:用rdt2.2的做法就可以解,再加上一個countdown timer倒數計時,時間一到就再送一次packet,就算真的duplicate也會因為receiver state不同而不會產生問題

幫助理解:

Pipeline
- rdt根本問題: stop-and-wait protcol效率太差,message傳遞間要等很久,大部分時間sender都在wait
Go-Back-N
- sender收到應用層的資料後,判斷是否window已滿,已滿的話不接受,還沒滿的話就把這個data送出去。
- sender設定一個timer 紀錄最早沒有收到ACK的packet,時間一到就再發一次,收到後會把window移到下一個還沒ACK的地方,若timeout,當下整個window資料會重送
- sender在收到自己expect的ACK後,window會向右移,若有data則在寄出data(因為原本那份收到ACK,所以window必定會多一個空位傳資料)
- receiver收封包要按照順序,如果先收到後面的封包不會理他(封包seq和receiver紀錄的seqnum不合),反而會回傳上一個他收到的封包
- receiver設定expect sequence number就是應該收到的packet的sequence,收到就送ACK,sequence number+1,其他狀況都送最近收到的ACK


- sender:
- rdt_send: 送data,如果window還有空間(nextseq<base+N)就送packet,如果他是第一個還沒ACK的封包(base==nextseq)就set timer
- timeout: 重新設定一次timer,然後把這個封包之後的封包都重傳(udt_sned(base+0~n))
- receive not corrupt: 就把base移動到下一個還沒ACK的位置(window移動),如果window有封包還沒收到ACK就settimer不然就STOPtimer(base==nextseq)
- corrupt ACK: 不管他,就等timeout

- receiver:
開一個sequence紀錄收到的packet順序,
- default:送packet
- rdt_rcv:收到正確的sequence且沒有corrupt,送ACK packet回去,然後expect seq+1

Selective Repeat
- GO Back N缺點: 若傳輸過程發生錯誤,會造成很多不必要的retransmission,影響performance
- 改良:
- sender:
- 跟GBN依樣,收應用層的資料,如果window_size滿了就先buffer或傳回上層
- timeout重傳
- 假設收到後面的ACK(seq_num>sender_base),而且seq_num在window_size內,就先把他登記ACK而不是丟掉
- 等到sender_base收到後,跳到下一格還沒ACK的位置,可能不只一格,因為後面的先收到會被登記收過ACK。
- receiver:
- 收到seq_num在[base,base+win_size],如果不等於base,那就先把packet buffer起來,送該seq_num的ACK,不用移動window
- 若收到packet=base,把window移到下一個還沒ACK的地方(可能移很多格,可能後面packet先收到),然後把移動距離的所有packet送給應用層
- 假設收到seq_num在[base-winsize,base]間,什麼都不動作,直接把對應的seq_num的ACK傳給sender(因為很有可能是ACK loss導致sender以為資料沒送到,但receiver是收到資料就右移,所以才會有落在這區間的packet)
- otherwise,不管他
- sender:


- 問題: 這兩種狀況對receiver來說是依樣的,他不知道收到的pkt0是現在新的pkt0還是舊的pkt0(base-winsize,base)
- 解法: window size <= seqnum/2(protocol裡的)

TCP
- 特點
- handshake(connection-oriented):先建立連結才傳資料
- protocol在end system:網路跟他關係不大(TDM,FDM那些事network layer在管的)
- full-duplex:同時兩方向傳資料
- three-way-handshake:總共來回三次,前兩次不傳資料,最後一次可以帶一些
- send buffer:應用層資料先傳到這個buffer,TCP protocol再慢慢把它傳給receiver,傳送資料的chunk最大為MSS(maximum segment size),主要大小受到MTU(maximum transmission unit)影響(link layer)規定能傳的大小量,故MSS+TCP/IP header <= MTU,所以一份資料會拆很多份來傳,receiver端也設定自己的一個buffer接收資料。
- Telnet只傳一個byte
- sequence number是取每個segment的第一個bytes來當作segment number(而不是第幾個segment),第一次傳的inital sequence不一定是0,可以是其他數字(雙方約定好即可,避免從0開始,收到其他人傳的封包)
- 保證對方收得到資料,而且能夠按照正確的順序、完整性(這些事Network layer沒辦法保證的)
- timeout的retransmission像GBN,只要維持最低的base unack位址即可,但是若先收到後面的data不會丟掉,會buffer
-
EX: 以Telnet(依次傳遞一個bytes為例),因為是雙向傳遞,所以sender,receiver彼此都有個inital sequence number,假設sender inital = 43 receiver inital = 92,當sender傳第一個bytes過去時sequence number是43,receiver ack number field就要擺44。相反如果receiver送資料過去number要擺92,sender傳ack回去要擺93
- 封包格式:

- source/dest port:負責規定送到哪個port
- sequence,ack num: reliable transmission
- receive window: flow control用
- options field: 用在協調MSS大小(和receiver端),快速傳遞
- PSH : flag的部分,要求receiver馬上把資料傳給上層
- URG:flag,sender應用層覺得資料緊急,匯改這個bit
- Urg data pointer : 指出data哪部分是urgent
- R flag : 當TCP connection client要連的port在server並沒有該socket,server會回傳Reset flag=1告訴client那個port並沒有socket在listen
- seqeunce num & ack num:
- 送資料:假設MSS=500 那第一次封包seqnum=0 第二次封包seqnum=500第三次=1000…… seqnum是byte-stream,是第一個在segment裡的data byte
- cumulative acknowledge: 傳的ACK num是預計下一個要收到的封包,例如上面例子收到第一個封包後,回傳ACK500。如現在base是500又收到一個500byte packet回傳1000 ack
- retransmission:如圖二,假設沒收到100 ack但是收到120 ack,依樣可以確定receiver有收到100的封包,所以不用執著於要收100 ack



premature timeout:如果收到的是之前的封包,receiver會回傳現在的ack的base的封包
TCP RTT
原因:TCP傳封包要設timeout,timeout時間要參考RTT來設定 simple RTT:資料從sender傳過去到receive ack這段時間,TCP一次只計算一個unack的transmission的RTT,不計算retransmission的封包。 Estimate RTT:如果只計算單個封包RTT,RTT會嚴重受到當時congestion的狀況決定,所以改用Estimate RTT(Average RTT):
Estimate RTT = (1-a) * EstimateRTT + a*SimpleRTT
Fast retransmit algorithm:
如果在收到三次依樣的ACK,但還沒timeout,就自動設定為重傳。

spec:
- 如果收到的data是inorder,而且之前有ack還沒送出,就馬上送出最新的cumulative ack過去,例如收到92-100後馬上收到100-106就送出106 ack不管100 ack

Flow Control
- 定義:recevier buffer收資料速度比sender送資料速度慢,導致data overflow
- 作法:
-
receive window:讓sender知道有多少剩餘的buffer空間
receiver lastByterecv - lastByteRead < RecvBufferrwnd = RecvBuffer - (lastByterecv -lastByteRead ) - receiver把rwnd的值放進TCP header的recv_window告訴sender還有多少空間
- sender維持兩個變數LastByteSend,LastByteAck,並透過收到的TCP ACK封包來計算送出去的封包-ACK的數目比rwnd小
LastByteSend-LastByteAck < rwnd
-
TCP Connection
- SYN packet:上圖的TCP header裡有一個S(SYN)的bit,是一個special bit,只有用在建立connection時用,當client要連接server時,先發送一個封包,這封包沒有任何應用層資料,只有把SYN bit設成1而且選取一個random number當成sequence number放在sequence number field。
- SYN ack: server在收到SYN packet後會allocate buffer、variable給這個connection(但也因為耗資源易受到DDos攻擊),這個新packet會包含三樣東西
- SYN bit設成1
- ACK field改成client送過來的seq_number+1:代表server確定從client給的seq_number開始傳 ack
- server_ISN:server自己設定一個inital sequence number給client(也是放在sequence number field),告訴client server資料從哪個seq_number開始
- connection granted packet:client收到server送來的SYN ack後,也自己allocate buffer variable來接受server資料,這時傳一個封包把SYN bit=0(已建立連線不用SYN bit),並把封包的ack_seqnumber設成server_ISN+1,這個封包就可以開始傳資料。
TCP disconnect
- FIN packet: client要終止和server連線,傳一個封包把TCP header的F設成1,表示FIN
- FIN ACK: server收到client送來的FIN packet後傳一個FIN ACK回去給client
- server FIN packet:server送完FIN ACK以後自己也傳自己的FIN packet給client
- time wait: client收到server傳來的FIN data後進入time wait並送出FIN ACK給server,time wait過後把資源free掉,server在收到client傳的ACK後把connection closed掉,資源free掉。

統整:

Congestion Control
- 定義:太多資源同時在網路上傳送,除了壅塞還會造成router queue overflow
- 分析不同case造成的throughput,throughput越低就代表資料傳輸沒效率,更容易造成許多封包重傳造成congestion control
- Case 1: router buffer is infinite
假設sender傳給receiver,中間的router有無限的buffer,但是只有R的transmission rate
Lin => 應用層data到network layer的速率(在這裡和進入network的速率依樣)
Lout => receiver收到的data
C => router的 capacity
C/2 => 因為TCP是雙向的,所以單向傳輸的Capacity設成C/2
當資料量小於C/2時送進去資料等於送出資料,但當資料大於C/2時,最多就只能送出C/2的資料
但當資料量>C/2時,因為送出去速度太慢,導致資料queue在router buffer裡面,造成嚴重delay

- Case2:router buffer is finite(drop is buffer overflow)
Lin => 應用層傳資料到TCP layer的速率
Lin’ => 資料傳進網路的速率(包括第一次傳送的封包和之後的retransmit的封包)
Lout => receiver收到資料的速率
1. 假設client知道router buffer有沒有空位來傳資料:因為知道有沒有空間,就不會發生retransmit(buffer overflow的情況 這時Lin = Lout
2. 假設client在知道封包遺失所以retransmit:這時候因為有些資料retransmit所以Lin’ != Lout,throughput下降
3. 現實情況,sender可能retransmit一個沒有drop的封包(可能queue在router裡)
因為recevier只需要一份data,所以router同時傳了原本data加上retransmission的data造成浪費
下圖顯示,假設R/2的每個封包都因為傳送時間過長所以timeout導致retransmit(但原本封包沒掉),造成傳R/2個data但有R/4是retransmit,所以實際上只有R/4的output throughput

- Case3:Four Sender Multiple path limited router buffer 問題:假設有一邊兩個sender互傳資料非常大量,導致整個router都放滿他們的資料,其他人就幾乎不能傳資料(router被另外兩個sender佔滿),產生starving的現象。
Congestion Control Approach
- end-end congestion control:網路層沒有辦法偵測congestion,只能由TCP layer end system透過packet loss來偵測congestion loss,所以縮減window size來舒緩congestion問題
- network-assisted congestion control:透過single bit回傳給sender來判斷有沒有congestion
- congestion window:cwnd,跟rwnd很像,只是cwnd用來看congestion的,故公式改寫成:
Last byte send - Last byte ack = min(cwnd,rwnd)sending rate = cwnd/RTT/2傳送的資料的速率就等於自己的cwnd除傳過去所需要的時間 - TCP self-clocking:TCP偵測到網路的congestion狀況來動態調整自己的window,作法就是藉由收到的ACK後做調整,假設網路沒congestion,sender收到ACK速度就快,congestion window增長速度快,反之若congestion,則收到ACK速度慢,window增長速度慢。
Congestion Protocol
- 若偵測到packet loss就認為有congestion的問題,縮小window
- 若ACK傳來都正常,代表兩邊溝通是沒有問題的,window加大
- bandwidth probing:sender若在收到ACK狀況都正常下,會增加傳送封包的rate,直到發生loss才把rate降低,因此是收到ACK以後動態調整congestion window,每個End system是async的(自己個別調整自己的)。
- FLOW CHART:
- slow start:剛開始congestion window size先設成1,如果順利收到ACK就double下次要送的封包數,即每收到一個ACK增加一個封包。
- threshold reach:如果到threshold,代表可能快congestion了,就不再double封包,如果順利收到ACK,下次只增加一個封包,即每收到一個ACK增加MSS/cwnd個封包
- packet drop:如果發生packet drop,代表發生congestion,threshold=window size/2、congestion window size回歸1重新slow start
- fast recovery:因為三個同樣的封包也會被歸類在congestion,但實際上network資料還是有在傳送,所以window=1的penalty太高,所以修改。
cwnd = threshold+3(3個duplicate封包)threshold = window/2如果在fast recovery state收到重複ack,一樣cwnd+1,若收到非重複的ack,就進入congestion avoidance state(並把cwnd設成thershold),若遺失則進入slow start state

- TCP throughput: 忽略slow start,window = w,在沒有封包遺失時,throughput是w/RTT,在封包遺失後threshold為w/2,output是w/RTT,平均是0.75*W/RTT
TCP Fairness
若K個TCP connection共用R bandwidth,每個人應該分到R/K的bandwidth
如圖,剛開始1的window size比2大,但兩者都還沒達到R,所以一直在congestion avoidance階段,雙方各增加1,所以是45度增長,到超過R時兩人的window size各除2,因為1的window size較大,所以除2減少較多,反之2的window size除2影響較小,最後兩者會趨於45度線到相等的window size
