LLM簡介
28 January 2024
出於對LLM的好奇, 因此看了一些影片簡介LLM, 並且把心得記錄下來
Reference
什麼是LLM
LLM(Large Language Model) 簡單來說就是一個智慧對答的機器人, 如chatgpt等等, 能夠回答使用者所詢問的問題或者指令. 叫做Large language model的原因在於一個能夠有好表現的對答AI模型, 會需要非常大量的資料以及非常多的參數來訓練.
LLM這項技術出名是由chatgpt開始, 使用了非常大量的語句資料庫(約50GB資料), 以及大量的參數(數億個參數)訓練出來的模型, 而這兩個條件也是一般人所達不到的, 沒有那麼多的資料量外, 也沒有足夠的運算資源來做此AI model的訓練. 但後來Meta有推出Llama, 是一個一般人, 學術機構能夠訓練的語言模型.
LLM的原理簡介
In a nutshell, 基本上可以分為幾個步驟:
- 預訓練: 透過語言資料庫,進行詞語接龍訓練,也就是給一段話, 然後算出後面接各種句子的機率
- 監督式學習: 有了詞語接龍後, 接著有點像fine tune, 透過人類導師, 告訴gpt某些情況應該要回哪些東西而不是接龍
- reinforcement learning: 有前兩部後就有一個還不錯的model了, 接著要做的就是reinforcement learning, 邊給使用者使用, 邊透過使用者的feedback來進行模型改善.
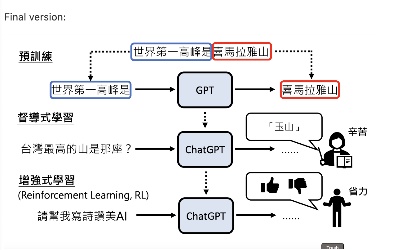
預訓練
監督式學習失靈
LLM可以簡單說成是一個智慧對話機器人, 也就是說他的input output space都是無法計算的大的, 就算針對同一句話, 前後文不同所需要的回覆也不同.
因此這件事就是supervised learning沒辦法成功做出智慧對話機器人的原因之一, 因為input/output space太大, 我們沒辦法把足夠的input space label成output space(況且一個user問題可以有多個合理的回覆),
預訓練與文字接龍
因此在第一個步驟,會採用給予一個大型的語言資料庫, 讓AI model (transformer)自己去學習看到哪些句子後面接各種句子的機率為多少, 因此這樣就可以讓他至少對一個user input產生一個合理看得懂的回覆.
而這個機率是有隨機性, 也就是說後面接的每個output都有一個機率, 然後選一個出來, 因為如果每次都選機率最高的那個選項很容易造成loop, 就是都在講同一句話, 可能某些字串到後來會變這樣, 因此會從機率裡面取一個出來(根據機率大小), 這也造成同個input每次output出來的答案不一樣.
預訓練的問題
預訓練是基於語言資料庫來做文字接龍, 也就是說他有時會有bias, 舉例而言, 如果今天語言資料庫裡面有很多的考題(例如一個問題後面接四個選擇題選項那種), 這樣訓練出來的LLM模型, 當user input一個問題時, LLM模型高機率不會output該問題的答案, 而是output那四個選項要使用者自己選出一個正確的, 這就是文字接龍的壞處, 因此會需要下一步的監督式學習讓人來做fine tune.
監督式學習
細節Chatgpt的論文沒有敘述, 但基本上這邊就是人為去label一些QA問題, 去fine tune LLM, 例如給予一個問題時, 不應該給user四個選擇題選項, 而是應該直接回覆答案這種, 又或者是user問推薦的網站, 連結部分不能是LLM自己靠文字接龍創造出看似合理的url, 但其實根本沒東西.
增強式學習
這時已經有一個可圈可點的model了,要再更近一步提升使用性跟準確率, 就是要真的跟user互動, 從user的feedback中改善模型, 例如接著就是user可以對gpt回答按like or dislike, 那這樣gpt對於dislike的answer就可以去降低機率, 對於like的答案可以提升他的機率這樣
但增強式學習的前提在於本身model已經有一定水準跟準確率, 不然太爛user的feedback永遠都是dislike 那這feedback就沒什麼意義了
如何使用LLM
- 把需求講清楚, 例如要翻譯成什麼語言, 要用什麼語言回覆等等
- 提供範例給chatgpt, 希望他以類似什麼樣的形式回答或進行
- 鼓勵chatgpt想一想
- chatgpt本質上還是使用文字接龍, 當問一個問題時, 請他列出詳細的過程再給解答, 準確率會比直接請他給解答還高, 因為前者文字接龍有更高機率接龍到我們希望的答案
- 大問題先請chatgpt break down成小問題 (讓chatgpt做計畫), 小問題在請chat gpt逐一回答, 準確率會比直接問一個大問題準確, 因為大問題scope大概很難描述清楚
- 模型是會反省的,可以得到更準確的答案
- 當問chatgpt一個問題時,他可能會回答一個不甚滿意的答案(如違反道德, 或者不實際等等的解答), 可以再把你問的問題以及chatgpt的回答貼上去 在問一次chatgpt 上述對話是否有哪裡不合理or不實際. 接著chatgpt就可以進行反省, 並且給出一個更好的回覆及答案.