AI Agent 簡介
19 February 2026
Reference
什麼是AI Agent
一般的AI: 給定一個明確的任務,AI根據這個任務去把事情達成,如翻譯、圖片辨識、智慧問答
AI Agent: 使用者給定AI一個目標,並定義好reward function(什麼結果是好的什麼結果是不好的),AI透過觀察環境以及reward狀況來決定行動,自己透過不斷的observation, Action的迭代來達成目標。
AlphaGo就是一個AI Agent的例子,目標就是要贏棋局,而我們給他的reward function就是他一連串的下棋決定最終是贏還是輸。而這個就是透過Reinforcement learning達成。
AI Agent And LLM
在Before LLM時期, AI Agent是透過Reinforcement learning方式,讓研究人員調整reward function來訓練AI Agent來完成指定的目標。但這會衍生出一個大問題:
對於每個目標都需要研究人員設定、調整reward function來訓練一個專們的AI Agent,這件事很不scalable
但LLM的出現很大部分解決這問題,研究人員目前研究目標為LLM As AI Agent,透過LLM可以產生一個generic的AI Agent來達成各個目標而不是為每個目標自己制定Reward function來訓練專門Model。
以上數AlphaGo為例,用LLM方式將變成我們把圍棋規則輸入並告訴LLM根據這個規則目標是要贏,定義什麼叫做贏,接著就讓LLM自己去觀察棋局自己去做Action。又或者用LLM作為AI Agent來寫code,我們不用定義reward function只要提供compile log就可以讓LLM觀察知道下一步行為、是否有compile error/warning要修,而不用像早期reinforcement learning需要定義reward function。
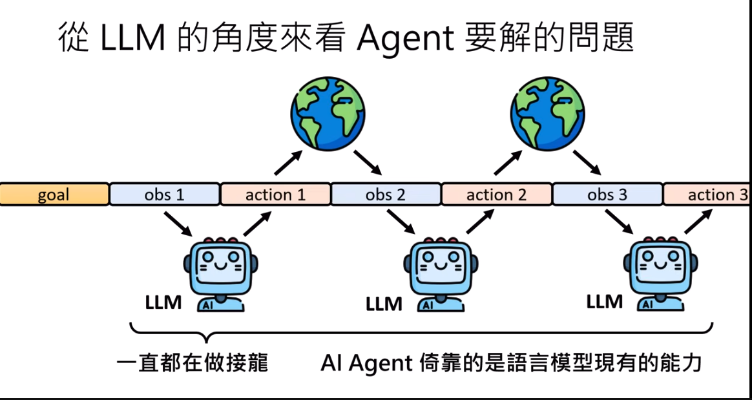
以一個寫程式的AI Agent,他的流程會如下:
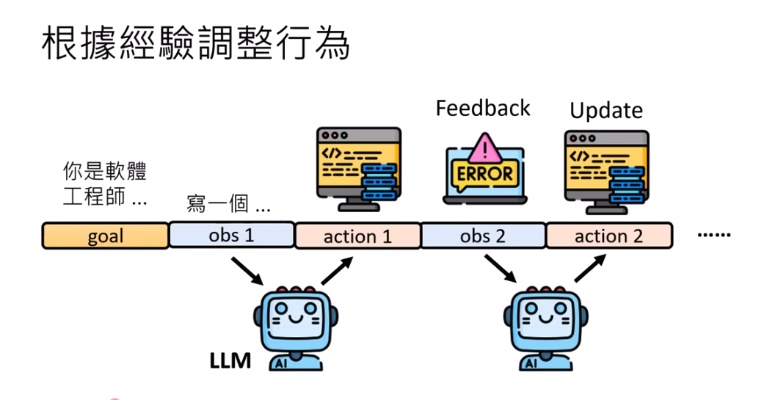
AI Agent Memory
就如上述AI Agent不斷透過feedback來更新模型進行新的action。這方法會有一個問題:
當整的AI Agent / LLM 收到的問答過長,這會導致AI Agent / LLM有過多的資料要讀取來為之後的Query / observation做反應,因此會有類似遺忘的功能或者資料庫功能,LLM每次的Query / Observation 只根據過去數個問答經驗來做出反應而不是瀏覽以前的所有問答來做出反應,這會減少反應時間外也會減少很多雜訊(很多問答或者觀察與這次觀察無關,因此不需要拿該次經驗來處理這次問題)。
AI Agent如何使用工具
LLM本質上就是一個對話機器人,因此很多問題如果我們需要串工具就必須教LLM如何使用工具,而這部分的串接以及工具開發,就會仰賴工程師的幫忙搭建好。以下面例子要LLM幫忙查詢天氣、氣候,工程師先利用AI / 自己開發好工具,並且在system prompt中教LLM這個工具使用方法 (e.g. input格式、地點、時間等等),然後跟LLM說當找不到答案時可以呼叫這個工具來找到答案,接著利用串接好的工具來得到答案並回傳給使用者。
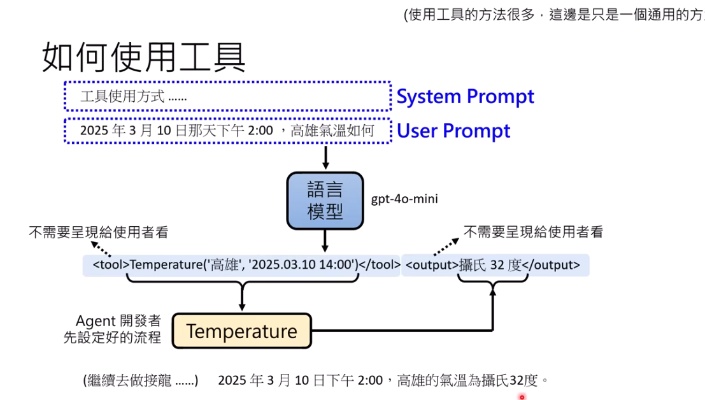
目前最廣泛運用的做法就是搜尋引擎、做圖軟體、以及使用語音辨識來讓LLM變成可以透過語音對話機器人。以及NotebookLM, 透過工具去讀pdf檔案來找答案。
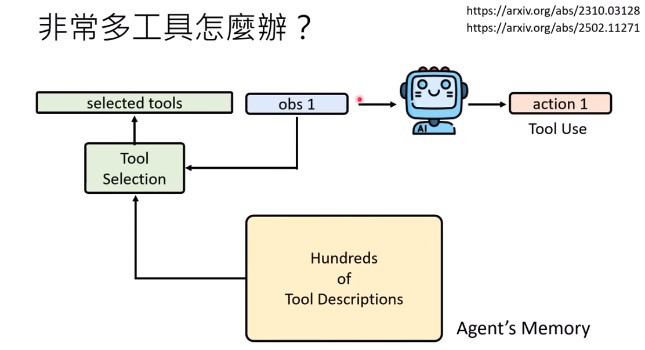
一個挑戰是AI Agent可能會使用很多工具,要如何讓AI挑選適當的工具來解決問題是不容易的,解決方法就會像上述AI Agent Memory的方式,與其讀取每個工具並判斷要用哪個,不如用一個memory,讓AI Agent不用每次都讀取所有工具來判段要用哪個,而是一個功能判斷現在問題要用哪些工具並給LLM使用。
LLM 做計劃
使用LLM做計劃時,一個增加可性度的做法是請LLM產生多個Plan 並且分析並切詳細敘述這幾個plan要怎麼執行,透過這樣更能夠有更好的結果
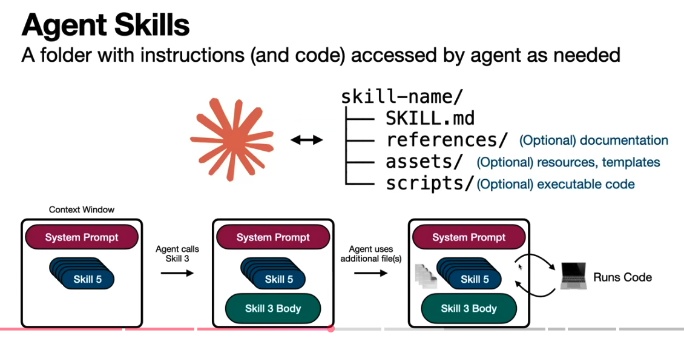
Agent Skills
當我們今天需要Agent做複雜的事情時,往往需要下多個prompt,以及過程中可能會走歪要把它導正,而下次要做一樣的事情高機會會遇到一樣的狀況,因此我們為了讓AI Agent能夠更快理解並執行複雜的任務時,我們會使用Memory / Markdown形式,有點像是一個筆記,讓AI Agent能夠偷看筆記來執行複雜指令。舉例而言,當我們需要AI幫忙解coredump時,我們會希望他知道要去哪裡找需要的unstripped library跟執行方式,下prompt溝通這件事情蠻麻煩,所以可以請LLM生成一個Markdown記錄這些指令,例如該如何編譯binary,該去哪裡找unstripped library等等。
此外skill.md (gemini.md)還有另一個用途是今天AI Agent有很多工具,當一個prompt下來, AI Agent可能需要去iterate所有工具 (mcp client去跟mcp server要lists of tools),看哪個才是我們需要的,這份小抄也可以記錄說哪些領域的問題我們應該用哪些工具解決,這樣就可以減少很多client, server溝通詢問要哪個工具的流程,也可以減少使用錯工具的機會。
Skills可以是一個LLM生成的Markdown,也可以是必要的執行script讓AI使用 (e.g. pdf parser等等).
Reference:
Model Context Protocol (MCP)
MCP用途主要是提供一個通用的協定讓不同的LLM模型都能透過MCP這個規範來使用其他的工具、例如Github、Cloudflare等等的工具。
為何AI Agent需要MCP才能使用工具
以往在沒有MCP工具以前,LLM就是個對話機器人只能把指令傳輸給User, User自己去照著做來完成任務 (e.g. AI告訴使用者要打什麼指令、要去哪個網站做什麼事情,最終仍需要使用者實際操作)。即使我們擴充LLM請他去做這些事,也極有可能因為網路上資訊錯誤、而導致AI Agent執行指令失敗 (e.g. 權限問題、生成錯誤網址等等),再者,AI完成這些任務方式通常是自己寫一個python script來完成,而這些script容易有問題以及非常不scalable,每個LLM做法可能也都不太依樣。
因此為了能真的讓AI Agent正確使用工具,最好的做法當然是提供一個手冊跟AI說應該怎麼使用工具,而我們可以想像這手冊的格式就是MCP,只要各家工具能依照這個格式寫手冊,就能夠讓AI Agent正確去讀取MCP並且使用工具完成任務。
Reference:
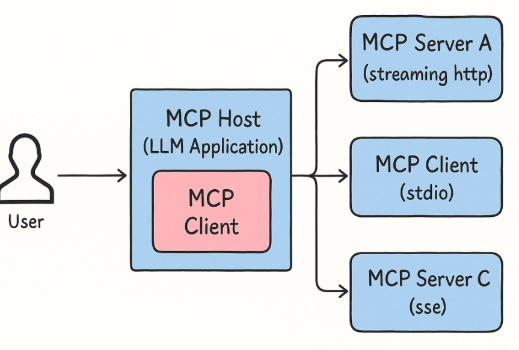
AI Agent 架構
基本上會在Local端跑一個MCP Host(通常內建於IDE中,如claude Desktop, VSCode等等),MCP host會去跟MCP server (tool provider, e.g. github, cloudflare, figma等等)通訊並使用工具。
要使用不同tool provider的工具,只需在local端設定好MCP的config檔即可。
教授們對於AI Agent的看法
AI Agent固然有機會提高生產力,但必須在正確的使用情況,不然容易產生over-engineered、不符預期的code。因此教授們提供一些建議該如何使用AI Agent.
Building it with piecemeal
重點是把AI Agent當成intern,與其一開始叫他做大的專案,先把問題切成小問題,讓每個問題給AI Agent解,這樣會是更有效率地使用AI Agent的方式。
Conetext Switching
當開始有多個AI Agent幫忙做事的時候,使用者的context switching功力就是很重要事情,要能記得每個Agent在做什麼以及做到哪裡,有好的Context switching功力才能夠讓AI Agent把每件事情做好。
Agent-friendly codebase
- codebase最好有gemini.md或者up-to-date README.md讓AI Agent能參考,常發生的問題是README.md過時、和程式碼的內容不一致,這容易導致AI Agent讀到錯誤的資訊而產收不如預期的程式。
- 如果能使用design pattern, 這會讓AI更容易把程式進行擴充。
- 有完整的SPEC或者測試更能讓AI Agent產生好的、符合預期的程式