Thread
07 August 2020
Thread
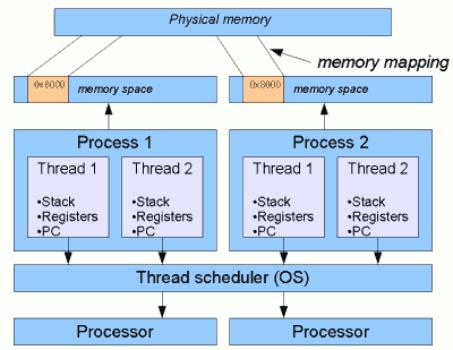
正常來講一個process內部就是一個thread,所以可以產生multi-process來達到平行化,但成本高。相對Thread的平行運算有以下特性。
- context switch成本較低
- 沒有新的process,create的thread都隸屬於同個process,所以dataspace, file descriptor都是共用的,在同個process內所有thread共用這些資源
- read/write各種lock thread也會繼承自process的(所以同個process內的thread會同時可以用同樣的open files, child process)
- 但另一方面也要確定data沒有dependency的問題,不然依樣會有data hazard(race condition)的問題
- process在thread在,process亡thread亡,沒有zombie thread的問題
- Thread雖然共用dataspace,但他們其實stack,register是有分開的(從原本stack中切塊分給各個thread,沒在另外allocate這樣,但各個thread的stack是不太重疊的)
舉例而言,我們可以在一個process產生多個thread,每個thread就固定做一件事,這樣會相對好寫、也能減少程式的bug。尤其像是request,response這類型的,可以不同thread處理不同response,整體而言速度會變快。
Single CPU Core
雖然在只有一個CPU core的狀況下,那multi-thread, multi-process就是一個CPU不斷的進行context switch來切換thread。除了原本程式執行外,還多了context switch的overhead。但在有blocking或者IO的程式下,即使只有一個CPU可能還是可以加強效能,因為當某個thread進行IO或blocking時,另一個thread可以先進行,那就不會像single thread時block住,所以可能這樣速度的提升遠大於context switch的代價。
ThreadID
pthread_t pthread_self(void); 得到自己的thread的資料
TID就是thread的ID,但他不是global的變數,他有效範圍就在process內,即tid只有在同個process內才unique
Thread Creation
int pthread_create(pthread_t *restrict tidp, pthread_attr_t attr, void *startrtn)
tidp: 該位子的值被設成tid
attr: 就是各種attribute
startrtn: 起始的function(thread要執行的function)
每個被create的thread,process會從原本的大記憶體中的stack切一塊給thread用,所以所有thread分配到的記憶體都在process的stack裡面,但理論上彼此是不重疊的(區域變數的部分)
Race condition
同樣如果今天process裡main thread 產生了其他thread,如果main thready在其他thread結束前就結束,那其他thread就會出事,因為整個process被清掉,因此要確保所有thread結束才結束main thread。
另外要注意pthread id不能夠單純用tidp這個變數(參考上面pthread_create的function call)來得知,原因依樣是race condition。
有一種可能是pthread已經產生新的thread了,而這時main thread的pthread_create還沒return,甚至直到新的thread結束都還沒return from pthread_create,此時ptid如果是global變數的話,新的那個pthread可能會讀到舊的ptid(因為main thread還沒退出pthread_create,而讀到舊的ptid值,還沒把新的tid寫進ptid)
pthread_t ntid;
void printtids(){ print value of ntid}
int main(void){
err = pthread_create(&ntid,NULL,some_func,NULL);
printids("mainthread") // print tid of main thread
}
如果child thread執行printtids印global var ntid但main thread pthread_create還沒結束執行
那會造成ntid還沒被改成新的tid,所以child thread印出錯的tid
另外注意的是,因為thread是share dataspace,所以如果同個process內的thread存取global variable或任何相同資源,會造成改寫同樣的東西,race condition。
或者是舊的thread return後記憶體內東西還是保持在那,當新的thread create時有如果沒做好initialize variable,很有可能讀到上個thread的東西。所以有時要用malloc之類的來真正allocate記憶體,避免多個thread使用時存取同筆資源,而且要做好initialize跟cleaning。
Termination
- pthread可以自己return
- 被其他thread kill
- 呼叫pthread_exit,
pthraed)_join(pthred_t tid, void **rval_ptr)
tid: 要join的tid
rval_ptr: 結束掉的thread的回傳值,typeless要回傳啥都行,join的thread會收到這個內容
依樣結束的thread可以用pthread_join來取得exit thread的資訊。pthread_join本身是blocking function call。被join的thread會被轉成detached state,把她佔用的資源釋放掉。
如果join時那個thread已經在detatched mode了,那就會回傳EINVAL這個signal(代表error發生)。
Thread Control Block(TCB)
跟PCB差不多概念,紀錄thread的資訊,主要在context switch時要恢復thread所需要的資訊
Zombie thread
假設thread結束但main thread一直沒去join她,那就變成zombie thread
pthread_cacnel
pthread_cancel(pthread_t tid)
就是相當於逼thread tid叫pthread_exit,把它停止,收到thread cancel信號的thread可以選擇ignore或者用他的handler來exit。
pthread_cancel本身只是發一個exit的request給thread,他不是blocking。
pthraed cleanup handler
void pthread_cleanup_push(void *rtn, void *arg)
void pthread_cleanup_pop(int exec)
rtn: cleanup function
thread可以寫一堆cleanup handler決定thread結束後要做的事情,cleanup handler順序為push順序的相反,first in last out
當下面其中一種狀況發生時,就會trigger clean up function
- pthread_exit is called
- responds to cancellation request
- pthread_cleanup_pop被呼叫(exec不等於0,等於0的話為remove該handler)
注意,如果thread單純return是不符合上述條件,不會call cleanup handler,不過最好都是固定用pthread_exit來結束thread,如果有多個thread的話,用return結束thread好像會造成stack改寫,可能會改寫到其他thread的clean up handler(詳情見課本)。
mutex lock
因為thread是共用memory的,如果多個thread同時跑很有可能造成race condition,因此用lock來決定讀寫順序
# init lock
int pthread_mutex_init(pthred_mutext_t mutex, mutexattr_t attr);
int pthread_mutext_destroy(pthread_mutex_t *mutex)
return 0 if ok, else errNum
# lock and unlock
int pthread_mutex_lock(pthread_mutex_t *mutex) -> blocking,在要到lock前死都不走
int pthread_mutex_trylock(pthread_mutex_t *mutex) -> non blocking
int pthread_mutex_unlock(pthread_mutex_t *mutex)
Deadlock
以下兩種狀況會產生deadlock
- thread試圖lock兩次,第二次直接炸開
- thread可以再有lock狀況下再去要其他lock,這樣就有可能兩個thread互等對方放掉lock
pthreadlock with timeout
pthread_mutex_timedlock 可以設定alarm,超過時間就不要lock了
Reader writer locks
就是read write lock的意思,可以多個人擁有read lock,但一但有一個人有write lock其他任合人都不能有任何lock了
Spin locks
跟一般lock依樣,差別在於她block住時不是sleep,而是busy waiting,在等待很短時可以用,因為sleep就是context switch了,不想switch時可以用這個
Barrier
讓不同thread能夠sync的function,讓所有thread等待到所有thread都執行到某個point才繼續進行
pthread_join就是某種barrier(block直到另一個process執行到exit這個point才繼續)
fork in multi-thread env
在multithread的程式下如果fork一個process,只有那個fork process的thread被複製到新的process,其他thread不會複製。但這種環境下fork很容易造成問題
舉例而言,可能今天呼叫fork的thread有一些mutex lock,那所有的mutex lock(只要在同個process內的)也會傳給child process,那child process也就擁有這些lock,但因為沒跟parent process的thread做好sync,所以他不會知道何時要把這些lock free掉,因此可以使用下面的function
pthread_atfork 這function就是pthread_create外加fork handler清空mutex lock state
他做的事情就是先把所有資料lock住,fork出一個child process後,個別再把data unlock,因為copy-on-write,所以兩者改寫不同記憶體空間,變成兩個acquire的lock不會有衝突
Reference
critical sections
如果今天狀況事thread A呼叫fork,而thread B正取得mutex修改某資料到一半時。這時心得process的記憶體資料就只會有thread B修改到一半的資料。
attribute
客製化thread的設定(包括detach state, stack size之類的),會有一個init,destroy function來建立跟刪除attribute object
也會有set,get來設定、取得attribute裡面的值
因為thread是共用process的stack,而每個thread記憶體用量可能不同,因此才多stack size來設定thread會用到的記憶體量,如果某個thread用過量可以先malloc在把stack改大
int pthread_attr_init(pthread_attr_t *attr) // init attr structure
int pthread_attr_destroy(pthread_attr_t *attr) // destroy attr structure
當用完attr(即呼叫完pthread_create後用不到attr,可以呼叫destroy把attr刪掉)
如果pthread_attr_init有allocate memory給attribute的話,destroy就會把使用的memory free掉
Detatchstate attribute
detachstate: 如果我們對於thread的terminal status不感興趣,我們可以宣告thread為detachstate,可以透過下面函式pthread_detach或者設定pthread_attr
pthread_detach(tid): 說明thread的resource在結束時要馬上歸還,不用等
Re-entrant and Thread-safe function
因為共用dataspace關係,所以很多function都會有race condition的問題
re-entrant: 如果某function執行到一半出事下次回來從執行時,結果仍相同,不會因為上次執行到一半下次再執行時出錯
Thread-safe: function在多個thread狀況下仍能保證資料輸出正確
Thread-specific data
在thread模擬process的dataspace環境,即每個thread有個別的data,自己修改不會影響到其他人,對於希望在thread端達成少量的資料個別擁有很有幫助,或者用thread模擬process的狀況
詳情看課本,基本上適用key的方式來說明某些data是屬於誰的
Process and Thread comparsion
Process: define address space, resources, text, and etc
Thread: sequential execution stream only


我覺得block那個欄位有點問題,先不要看,thread有分user-level thread跟kernel level thread。
OS並不知道user-level thread,所以OS只會知道process是single user-thread, 實際上可能有多個user-thread,這是由使用者決定的. 所以OS找到的thread都是kernel-level thread. 如果看到某個process只有一個thread,也有可能是開發者用了很多的user-level thread, 但這也代表OS不知道這有多個user-level thread,所以沒辦法分配core給一個process就算他有多個user-level thread. 而且只要一個user-level thread做IO, OS就會判斷這個process在做IO所以就context switch(等於那個process的其他thread也沒辦法執行)
另一個process跟thread的差異就是有沒有共用記憶體空間,也因此如果對一個複雜的tasks而且會共用許多的記憶體空間之類的,用process會比用thread好,能避免很多難找的bug, 而且一個process掛掉把memory用爆不會影響其他process的使用, thread則會影響其他thread的運行. 這也是為何browser會是一個tab一個process, 避免彼此互相干擾.
Multi-threading Model
因為上述的User-thread特性, 如果只有單一kernel thread的話, 他其實並沒有辦法達到multi-threading的效果(就算開多個user-level thread, system也看不到, 他看到的就是一個process). 因此multi-threading model很重要, 這就要看呼叫的API他是怎麼時做kernel-level thread跟user-level thread的對應
1-M Model
一個kernel thread handle M個user-level thread, 這就是上述的問題, 看起來就是一個process, 所以只要其中一個thread block住或做IO, 其他thread也別想做事
1-1 Model
一個kernel thread配一個user-level thread, 這樣就能達到很好的multi-threading效果(似乎大部分的OS都採用這種方式, 所以thread間是不會block的)
M-N Model
M個kernel-level thread 透過multiplexing方式handle N個user-level thread
Reference: User-level Thread vs Kernel-level Thread
Multi-process & multi-threading
multi-thread fallacy
Reference
Process v.s Thread
thread tutorial
thread medium(including kernel,user level thread)