File system
21 September 2021
File system
資料就是存在disk上面的一堆資料,所以File system是一種軟體的實作讓我們方便管理資料,把相同相關的資料放在一起並給予命名標籤,方便使用者便是存取資料,也方便我們做新增資料、修改、刪除等等的interface讓使用者使用資料,此外, file system還提供了一個標準化的interface讓不同的Application能夠存取資料,包括OS提供的open,close,read,write, search file的功能外,OS kernel還讓這些system call能夠支援各種不同的device, 掛上device driver與各個storage device上的firmware做溝通。流程如下:
Application用自己的方式讀取資料 -> 呼叫OS system call -> OS kernel操作device driver -> device driver去storage device讀資料回來 -> OS kernel把資料傳回給application
以create file為例:
OS 要allocate一塊disk space來存這些資料,增加檔案的metadata, filetype等等, file descriptor和他對應到的disk位置,file type對OS的一個很重要好處是可以讓OS可以對不同類型的file有default action(例如執行binary, 打開text而不是執行text等等,用圖片編輯器開圖片)
mmap: 把某塊virtual address map到檔案的某部分,所以檔案資料會與這塊記憶體sync, 對這塊記憶體資料的修改也會修改檔案的資料,這樣就可以不用read/write之類的system call,單純只要修改memory的值就能夠修改file
User對資料的要求
- Persistence: 跟memory不同,資料要能夠一直保留著,即使application crash, 電腦關機,這些資料都還是要存在
- Disk本身是Non volatile,所以hardware能夠盡量避免這問題,但如果在memory操作時電腦突然crash,此時資料就沒更新到disk, File system就要有機制處理
- Speed: 希望讀資料越快越好
- Size: 希望能存越多資料
- Sharing/Protection: 能夠讓資料在不同的user或application間分享,並保障資料的安全性(confidentialty, Integrity )
- Usability: 資料只是一堆bit存在disk上,要有一套機制讓使用者能夠方便操控、閱讀這些資料
- OS把相關檔案label成file,並紀錄meta data(filename,location,access control,size…)
File table
global file table: process-wise的file table,記錄整個OS中有哪些檔案被開啟,以及開啟該檔案的process數量等等
per-process file table: 個別process紀錄目前開的檔案的數目,給予每個檔案一個file descriptor, 並會把該file descriptor map到global file table的entry, per-process file table還會紀錄file offset, 開啟的模式(r,w,r/w), 紀錄現在這個process在讀取還是寫檔案的哪個位置. Close file就是把該file descriptor從process file table上移除
File Access method
- sequential access
- 資料是照著byte的順序讀,大部分檔案都是這種模式,所以會有一個file pointer紀錄目前讀到或寫到檔案的哪些地方
- direct access
- key value based的資料存取: 如database, hash table的資料存取,所以他是有點像random access, 而不是sequential access
link
基本上就是檔案alias, 捷徑的意思,讓其他檔案路徑其實指到某個已存在的檔案
原因是一個完整的file的位置描述應該是directory + filename, 不同的directory可以有相同filename的file,這樣的問題在於file sharing會變成極其麻煩,因為directory還有access control, 例如user a不會想讓其他人瀏覽自己的home dir, 但想要把某個home dir內的file跟其他人分享,那就要設定好directory的access control
hard link(ln): 建立一個捷徑到某個檔案,基本上就是會建立一個name,這個name會refer到既存的檔案,檔案會有一個metadata(refer count)紀錄多少個hard link的捷徑指到現在這個檔案,當rm其中一個時 metadata的refer count -1,直到refer count變成0才會真的把檔案資料從disk上刪除, hard link的metadata會顯示該資料的大小
hard link本身有一個問題是會破壞file system的tree structure, 因為refer directory 可能會產生cycle, 例如dir refer另一個dir可能會在整個file system的tree中產生cycle。這會導致在search file之類的指令上產生infinite loop,所以hard link不允許link directory,link file就沒這個問題,因為file都是leaf node
每個directory在創立時都會建立兩個directory hard link(.和.. 一個指到現在這個dir的資料,一個指到parent directory的資料),所以 rm -rf ..就是把hard link ..的資料清掉,就是parent directory, 這是建立dir時會有的兩個hard link link directory的特例。
soft link (ln -s): filename alias, hard link是新的filename會point到同筆資料,但soft link是filename指到某個filename (alias, 相當於windows捷徑的功能), soft link的file metadata會顯示filename的大小而已(因為他只是filename alias). 也因為只是filename alias,他有可能是deadlink,例如指到的檔案已經被刪除(hard link上就不會發生)
Protection
- Access Control list/group(Windows NT): 每個file紀錄有哪些user有哪些權限
- Access Control bit(linux): 每個file指需要9個bits就可以紀錄access control list, user/group/all user各3個bits(rwx).
Hard disk
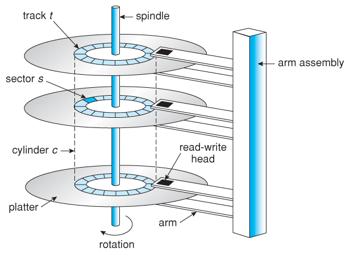
Hard disk是由多層的CD組成的,每層CD有多個圓圈,一個圓圈叫做一個track, track裡可以在分割成多個sector,disk的讀寫是以sector為單位,就算是只要讀寫一個byte,實際上會是操作整個sector。 disk會一直轉動,機械手臂就調整指到哪個track然後就等到轉到那個sector把資料讀出來(因此一次是讀一整個sector出來)。每層CD都會有一個機械手臂。
Hard disk讀取資料的速度取決於disk的轉速(手臂到了正確的track後要轉到該sector才能讀取資料)和disk read/write資料的速度(這兩個是資料毒取時硬體上的限制),相對的SSD的方式因為沒有可動的零件(沒有機械手臂),所以就少了等待disk轉到sector讀取資料的這段overhead。
但SSD有自己的硬體限制,如每段空間只能寫固定次數,固定次數後就不行。
Disk IO latency: seek time(移到正確的track) + rotation time + data transfer(bus,傳輸數度bps)
Disk優化
根據Disk IO latency的因素,加快disk的方法:
- disk小一點或增加轉速,這樣seek time, rotational time都可以更快
- schedule disk layout,讓相似或者常同時存取的資料放在相近地點,利用spatial locality的特性,這樣就可以有機會一次讀取讀到很多需要的資料
- disk block size: 跟cache, memory一樣的道理,大小很重要,小的話代表可能讀取資料要較多次的seek, block size大的話一次seek能讀取較多資料,但可能很多沒用,或者產生internal fragmentation的問題
Disk Head Scheduling
通過改變disk存取資料的request順序來減少disk seek time。多個資料存取request,可以把相近sector的request一起處理。這些disk request scheduling是實作在disk driver,由軟體來控制而不是硬體來做決定(比較容易更動和做複雜運算)
- First Come First Serve(FCFS): 先來的disk request先處理,就是沒任何優化的方法,但這個方法適合SSD,因為SSD沒有機械手臂跟轉動的track, 他更像memory的random access
- shortest seek time first(SSTF): 先處理seek time最小的disk request(最近的track),但肯定不是optimal,因為跟sector也有關,或者很多disk request的track都超小,就一個超大,那應該先把track超大處理完再去處理小的,不然小的處理完後還要把手臂移到最大的track那邊。另一個問題是starvation的問題,跟shortest job first一樣的問題,例如一直都有很多track很小的disk request, 那track大的disk request永遠不會被處理到,還有一個minor問題就是book keeping, 因為要有資料結構來存disk request的資料來做排序和額外的CPU運算來決定下個要處理的disk request是哪個,而這個資料結構就要存在disk或memory,但這overhead相對還好,畢竟結構存在memory的話,速度跟disk比快很多,所以增加的data structure不會是bottleneck。
- SCAN: 像電梯的方法, 會scan the disk in a back and forth manner, 所以往前時就處理掉前方的disk IO request,移到最大的track時再改變方向開始移到最小的track,過程也是有disk IO就處理,就是disk版的round-robin。但有一個問題是disk IO的hardware移動機械手臂到各個track的機制,機械手臂再移動到track的機制並不是等速,而是如果移動距離遠的話 他會有啟動速度跟中間的最高速度跟快到時的減速,如果像這樣round-robin每次掃來掃去,中間遇到就停下來,勢必會很難讓機械手臂移動速度到最高速度,反而都是在啟動速度下移動,例如從track 0到20花的時間會比track 0到10的時間的兩倍還少。所以這個round-robin的方式會讓機械手臂並沒辦法達到最高速的移動速率。
- CSCAN: circular scan algorithm,與其像SCAN back-and-forth的掃,這個round-robin方式都是從最小的的track到最大的track掃描,這樣移到最大的track會直接以最快速度回到最小的track,然後再開始網上掃,遇到disk IO request的track就處理,這個的理論基礎在於,現在track附近處理完後高機率附近不會再有disk IO要存取那個track(畢竟剛處理完)而是會在其他較遠的track, 所以例如我移到最大的track處理完disk IO, 基本上接下來有disk IO要處理大的track的機率不高(畢竟剛處理完),通常剩下的disk IO都是要處理小的track, 所以演算法是要立即快速移回小的track再重新掃到大的track。
Interleaving
雖然提到contiguous allocation能夠讓file content都存在相鄰的位置,可以有spatial locality,但其實未必這樣的performance會很好,因為從disk讀某個block資料到OS進行處理時,OS處理需要時間,而此時機械手臂仍在移動,當OS kernel處理完要讀下一個block的資料時,會發現此時hard disk的機械手臂通常已經移到其他較遠的block,反而要等到手臂回來才能讀取這個block,因此file content最好的儲存方法並不是contiguous allocation, 而是interleaving,file content儲存彼此間隔少數個block,把OS kernel處理資料時間算進去。這樣kernel處理完資料後剛好就可以讀取機械手臂指到的disk block。
Buffer size
如上述interleaving欲解決的問題,因為OS kernel處理資料要時間導致讀取資料的latency,另一個做法便是增加buffer size,例如要讀取file content在處理,OS在處理第一個disk block的content時,第二個跟後面的disk block可以先讀進來disk controller上的buffer(硬體上面的buffer)做存放,這樣file content就可以維持contiguous allocation,而不用使用interleaving改變disk storage layout,這樣之後讀取後續的file content只需要直接從disk controller buffer拿,不用再額外的seek time。 這個prefetch的做法適用於disk level(如上面所述),也可以做在file system level(此情況在於file content storage如果是unix之類的會是indexed file stoarge,當我們讀取前面幾個file block時,高機率後面的file block也會被讀取到,所以disk controller或OS可以在application還沒發出這個request前先把後續的file block讀出來放到disk controller buffer,做preseek的動作)
SSD
SSD很多方面優化了disk IO的部分,因為他就沒有mechanical moving part(沒有機械手臂跟轉盤),讀取資料跟memory讀取方式相對類似(flash storage),所以速度能較快,取資料速度快,但寫資料速度相對慢(erase舊有資料才能寫入而不能直接覆寫)且每個block有固定的寫入次數限制(產品壽命)
RAID
mass storage with reliability, 把資料存在複數區域備份,在大型的server環境,Data center尤其重要(disk數目多,有disk壞掉的機率就高)。
Disk striping(RAID 0)就是把多個disk當成一個儲存空間使用,把資料分散存於這些空間,一來增進每個disk使用效率,二來能夠RAID有多個driver能同時讀取多個disk, 所以如果檔案內容分散存於各個disk, 讀檔時可以達到平行化的優勢,缺點是如果一個disk壞掉,那個disk裡存的當按區塊就永遠不見。
RAID 1就是避免disk striping產生的問題,使用數個disk當作備份資料用,所以當一個disk壞掉時,RAID會去其他disk讀取遺失的檔案,但這樣的問題是儲存效率差,只有一半的disk space能拿來存資料。更好的做法是使用parity check的方法來存一段資料的checksum, 只要用相對少的儲存空間就能做data recovery或者error detection。
File descriptor
filename, filepath這些是metadata, file descriptor才是真正OS用來描述一個檔案的identifier, 會有一個table紀錄這個file descriptor對應到的資料在哪
File Allocation
File是Software定義、呈現資料的方式,每個File下會紀錄資料(File metadata, file content)是存在哪個block,block相當於hard disk sector(一個block可以是多個sector,也可是單個sector,所以每個block會對應到hard disk的cylinder, track, sector)
fileID -> block0 -> cylinder 0, track 0, sector 12
fileID -> block1 -> cylinder 1, track 1 sector15
通常一個OS裏大部分檔案都很小, 然後大部分被佔據的空間都是少數很大的檔案佔據的,所以disk IO會同時要能讀取小檔案跟大檔案,所以OS file system對讀取資料的要求是在讀取小檔案時效能要好,讀取大檔案時也要效能好
Contiguous Allocation
OS透過一個ordered list紀錄free block, disk allocation給file時會allocate賢旭的disk空間,要紀錄每個file descriptor他在free block list的起點跟長度就可以知道檔案存在哪些block(因為是使用連續的空間)
好處是這樣的方法非常簡單,知道起點跟長度後,只要找到起點就可以一次把所有資料從disk上load出來,所以只要做一次disk seek找到起點就可以找到整個檔案的內容,要做file的random access也非常簡單
缺點是改變file size要重新做allocation(跟memory一樣的問題),然後會有external fragmentation的問題
這種演算法適合用於CD, DVD, storage tape這些資料放進去後就幾乎不改寫的case
Linked file
這種做法就是針對每個file descriptor,我們會用linked list方式存檔案使用到的disk空間,所以每個element就是一個disk block,block會存檔案內容外,也會存一些metadata,像是像一個block的位置。file allocation不一定是要連續的,反正都適用linked list指向下一個content的位置,優點是要改變檔案大小時只要多allocate一個disk block然後insert進去這個linked list
對於free block也是用一個linked list存取free disk block, file allocation時就從這個linked list裡面拿
特色是要sequential read整個file,需要O(n)個disk seek(每個linked list上的element都要一次disk seek), random access也是做n次disk seek,原因是linked file連結的方式,就是要透過取出那個disk block裡面的metadata,得知下一個node的disk location。
FAT, MSDOS是用這種模式
Indexed File
File descriptor會對應到一個pointer array, 每個pointer會指到一個特定的disk location,要改變檔案就對pointer array做操作即可
每次新增一個file OS就要建立這樣一個pointer array,但檔案越大pointer array就要越大,一開始pointer array裡的pointer可以很多都指向NULL, on-demand的做disk allocation。
這樣的做法sequential access還是要n個disk seek, 但是random access只要一次disk seek, 剩下可以在memory做pointer array的iteration
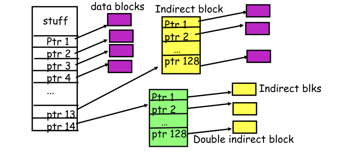
Multilevel Indexed file
每個file descriptor有1個array裡有14個pointer,前12個指向data block, 第13個pointer指向另一個有1024 entries的pointer array(這裡的pointer array的pointer就是指向data block, 一層的indirect reference),第14個pointer指向另一個pointer array of 1024 entries(這裡的pointer array的pointer會指向下一個pointer array(兩層的indirect reference))
這種模式的特色在於Indexed file的進化版,Indexed file的問題是對於一個file descriptor的pointer array要多大其實不好決定,有些檔案很大有些很小,那勢必就要一開始初始化把pointer array都設成很大,大不管如何都會有maximum file size的限制,不然就是要有一些複雜的機制增長這個pointer array使得每個file descriptor的pointer array大小都不同
Multilevel indexed file就是能夠讓Indexed file能夠簡單的support各種file size跟一些機制來存變得很大的檔案,就算file size很大也可以輕鬆地做到對應,因為pointer array後面兩個的特殊用途,一個用來指向更大的data block,一個用來遞迴的指向另一個pointer array,而一開始只存在1層indexed array,後面的indexed array是on demand allocate的,根據需要,檔案變大時才allocate。
這種file layout方式適合小檔案,因為小檔案可以在一層的indexed file簡單的做存取,但如果檔案很大那就有多層的indexed file,相對在random access的效能上會比naive做法有大一點的penalty,因為還要做2層之類的indexed file reference
這些file descriptor, data structure就是在Unix上的inode
所以file system安裝時(format disk),Initialize就是在disk上面allocate一些空間,建立好這些inode的data structure,然後建立檔案時就是file system會配置這些已經建立好的free inode給那個新建立的檔案
磁碟重組
目的就是disk defragmentation,想辦法讓同個檔案的儲存位置更連續,存取上更快
Free Space Management
要有一個方法紀錄disk上哪些block被使用,哪些沒有,一個方法是使用bitmap,每個disk block用一個bit紀錄有沒有被使用。這樣這個bitmap一樣要在disk上面allocate一個block來存bitmap,這個在很大的disk上會是一個問題,要存整個bitmap可能要不小的空間,再來如果disk使用率非常高,那就要花相對較久的時間找到free block。
因此alternative是使用free block linked-list使用linked list來存free block