Metrics
01 July 2020
目的
提供一個程式量化的準則,告訴測試者在某種條件下、測試某種程式邏輯時的分數。
Quality
在設計metrics時記得要注意下列問題
- 設計的metric是否符合自己想測的attribute?
- 此metric是不是能夠提供consistent result
- 此metric是不是能夠幫忙找出exception case、或問題,或者描述想要測的attribute的狀況(abstract concept)
Measure Target
- product: 檢測產品的特性(符不符合spec,code有沒有寫好…)
- process: 觀測程式的process使用的資源之類的,程式pass/failed testcase數量
- resource: 測試程式所花費的資源(cpu/mem)
Metric Usage
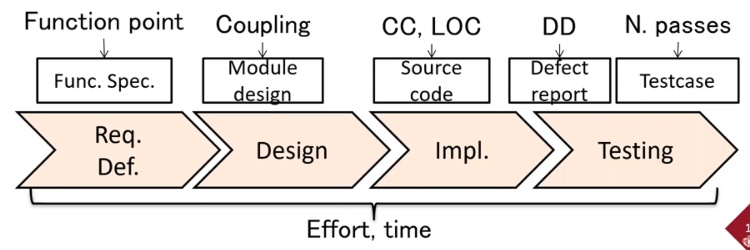
不同時段要用不同metric
但有些metric是任何時段都可以用來測量的,如time, effort,那就跟程式開發的stage無關了
Requests / spec
- Function spec/ Function Point: 可以用來評斷程式的大小跟複雜程度
- Function reused rate and number of function calls: 看function被call多少次,有沒有達到較精簡的方式,然後function都是有用的
Design
- Module design
Implementation
- Line of Code / CC
Testing
- Defect Density
- Number of pass/failed testcase
Sample Metrics
Cyclomatic complexity(CC)
描述程式condition的複雜程度
CC = number of binary decistion(if/else statement) + 1
or
CC = edge - node + 1
可以配合Line of Code來看某個function的複雜程度
Function Condition complexity: CC / LOC
Line of Code / Function Point
兩者都是用來描述程式大小的metrics,Function Point代表有幾個Function entry
其中Line of Code有各種不同執行方式,考慮到有些行數是comment或者只包含大括號。
- ELOC: 去除行數只包括空白、comment、括號之類的行數
- LLOC: 如果把多行statement寫在同行,也應該要算成多行code,所以變成計算statement數量
如何有效的計算Line of Code,例如加入weight(某些行比較重要,某些行沒那麼重要),或者有copy & paste的狀況。所以計算Line of code可以參考以下link
Defect Density
計算平均每幾行code有一個bug,可以評斷程式的安全程度跟開發狀況
- Defect Density / Number of pass testcase
Cohesion
針對module
描述一個module和其他module有多related,有沒有focus在單一的功能上,描述module複雜度
例如假設module存取很多不同的attirbute,那可能代表這個module有點複雜,要把他再切割成更細的module。
我們希望module裡的method存取資源差不多,代表他的功能比較單一。
Lack of Cohesion methods(LCOM)
計算module裡面的method,存取attribute的狀況來描述module的method的複雜度、功能性,例如一個attribute會被多個method存取,那這個module功能比較集中,method存取的資源狀況差不多,比較好。
相反如果各個method存取的資源就不同,代表不同method之間功能可能比較沒那麼重疊,此時就可以把比較獨立的method(不會跟其他method搶資源的)獨立成另一個module。
Coupling
描述程式中,不同module depend on other module的程度。
Fault-prone module prediction
大多數的bug會集中在少數幾個module,透過上面metrics當作變數訓練model來預測哪幾個module有更多fault
- module: class, method, function
- explanatory variable: line of code, complexity等等
- objective variable: number of faults/defects
- prediction model: ML model
Evaluation
有了上述提到的metrics做measurement後,接著就可以從結果來做evaluation,例如值介於多少是可接受的etc。 然後收集所有metrics的evaluation結果後給出final results。
不同metrics有不同測量基準,例如有的metric值越大越好,有的越小越好,而且可能是不同scale,例如一些metric值只可能是0 - 10有的卻可能是好幾千。這樣會很難統合不同metrics,很難做比較
所以我們給一個scoring system來做normalized。例如某metrics的值是多少是map到score是幾分