Container
02 October 2021
OS level Virtualization
- 原本System VM是透過VMM來分配共享硬體資源給各個VM, 每個VM可以跑自己的OS kernel跟多個不同的process
- OS level Virtualization則是多個user-space instance共享一個OS資源, 由Host OS來做資源分配, host OS上面可以執行多個process, 每個process是一個isolated的user-space instance
- OS會提供多份同樣的function, 功能給這些不同的process instance(containers), 所以Host OS會提供各種container system call來服務各個container裡的process, 每個container只是process而沒有完整的OS kernel
- 這樣的優點在於安全性, 能夠確保process彼此執行不會互相影響, 而且能限制process的資源使用量, 也能提供portability, 可以輕鬆把它移到另一個地方架起來, 而且輕量級,因為各個container不用跑起一個OS kernel所以跑起來的速度更資源使用量都比較好
- 實作方法包括Container(Docker, Podman, OpenVZ)
- LXC: 利用linux kernel的function弄的container
- chroot: 限定某個process只能瀏覽特定資料夾以下的範圍,
- 所以等於對這個process來說, 他的root dir就是那個特定的dir,
- 所以在這個特定資料夾裡面創etc,bin,home之類的dir
- 問題點是只有dir isolation, IO device並沒有做isolation,所以chroot的process可以去mount disk到自己現在的地方就可以去讀disk裡其他process的資料, 然後還有各種不同的escape方法
- 另一個問題點是怎麼建立好chroot dir(預設的/etc /bin之類的)的設置給application, 因為不同application的這些dir設置可能會有些dependency的問題, 所以要chroot設置好這些資料夾裡的檔案讓application跑起來不容易
- FreeBSD
- chroot加強版(修好一些escape漏洞) + kernel功能來達到process,resource isolation, 每個jail有自己的virtual IP之類的
- 主要元素有directory subtree, hostname(jail名稱), ip address, command
- 先開啟一個jail process, jail proces fork要跑的proces, 所以所有process都是jail process的child, jail裡面的process只能跟彼此溝通, 不能跟jail外面的process溝通
- BSD allocate一個struct prison的資料(類似PCB之類的東西)來存jail的資訊
Container
- 所有container都是跑在一個Host OS上(Host OS實現isolation), 通常Host OS跟container中間有一層Container Engine來連接container跟Host OS
- 一個isolated的環境, Container裡有自己的file system, process id, IO space, 但都共用host OS kernel
- 整個isolation是由OS提供, OS提供每個process一個獨立的環境, 包括自己的file system, CPU, memory使用量,user id,pid等等(所以相對沒有VMM那樣的Isolation做的好)
- Process Isolation: 讓process覺得他是為一一個在裡面跑的process
- 很多vendor都有自己的container實作,所以要有一套整合的方法和規範, 讓其他tool能夠跟不同公司開發出來的container做整合
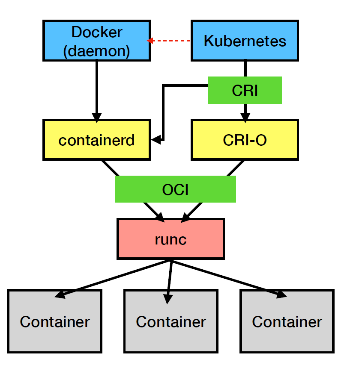
- Container Runtime Interface(CRI)
- Open Container Initiative(OCI)
CRI
k8s提出來的, 提出k8s怎麼跟container溝通的方法(這樣就可以把k8s跟各種不同vendor提供的container整合, 不用限定docker),所以就可以跟container runtime溝通(例如docker containerd, CRI-O),讓k8s能夠管理container的創立之類的
docker就是利用containerd來讓docker container能夠跟k8s做溝通讓k8s管理container, 其他的vendor則可能是用CRI-O
OCI
一群公司定義Container的image, 跟OS kernel(更底層software component)溝通的規範, 如何實作container, image跟distribution的規範跟format之類的
runc則是符合OCI規範的container runtime, 由docker用golang所開發,相對於CRI的component runtime是一個low-level的container runtime負責跟OS kernel做溝通的component, 包括創建新的container或者依些資源的分配.因此high level container runtime(CRI規範的container runtime) 其實最終還是會到runc來真的跟OS kernel溝通創建container之類的
Docker
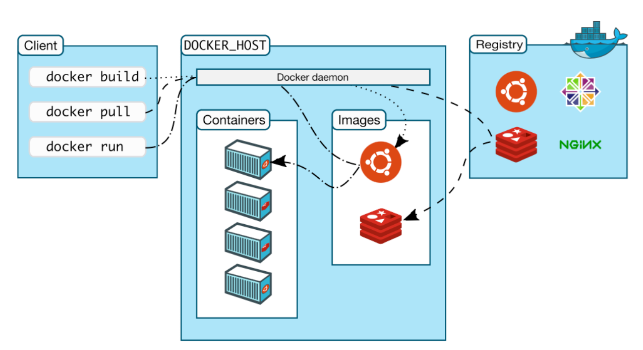
- client server架構, client(docker-cli)下指令(docker build, docker run)會送到docker daemon(engine), docker daemon可以跑在local或remote都可, 中間透過rest API傳送資料, 然後daemon再根據client給的指令去registry抓image或者跑起container之類的
- 早期使用LXC, 後來改用自己開發的libcontainer
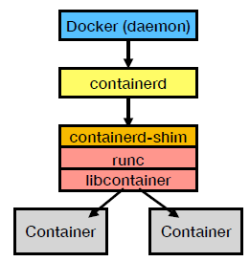
docker的架構, docker engine收到request會送到containerd, 然後一步步傳下去最後由runc真的設定好資源建好container
docker run -it ubuntu /bin/bash
1. docker engine先檢查本地端有沒有image, 沒有的話去remote registry pull
2. docker跑起container, 建立read-write filesystem到container裡
3. docker用bridge的形式建立network interface然後執行指令
Docker Container Kernel Mechanism
Capabilities
基本上就是ACL, 給每個container裡的process不同的權限, 每個權限就是一個capability, process要做某些事的話就要request capability(例如: CAP_CHOWN,CAP_NET_ADMIN, CAP_SYS_ADMIN, 有不同CAP可以做的事情就不同)
基本上就是一組bitmap給每個process或file, bitmap就是每個bit紀錄有沒有那個cap, file的cap就是執行那個file時有的cap有哪些
container很大部分就是用這個linux的ACL feature來控管container的process的權限(運用OS的feature來做到isolation)
指令來查process/file的Capability
$ cat /proc/$PID/status | egrep "Cap"
$ getcap/setcap來修改file/process的capability
cgroups
linux裡負責規劃process,file資源allocation, 設置單個或多個process的資源使用上限, 如果資源使用超過cgroup上限就會被kill掉
- Resource limiting: 設置cpu, memory, device使用量(例如設定這些process只能使用哪幾顆cpu)
- Accounting: monitor resource usage
- Prioritization: 可以讓某些cgroup資源使用優先度最高
- Control: control process state(restart/suspend…, cgroup所有process同時restart,suspend)
$ cat /proc/cgroups 可以看到linux內部先定義好的cgroups
用cgroup-tools裡的cgcreate,cgset,cgget之類的指令來管理cgroup
$ cat /sys/fs/cgroup/memory/....
cgroup在linux裡用vfs方式實現, 所以可以去讀檔來得到cgroup資訊
Namespace
- linux裡virtualize,partition讓process可以看到的Kernel的資源(cgroups是限制process可以使用的資源, 概念上有點不同)
- kernel把資源打包(abstraction),然後提供給各個namespace,所以namespace裡的Process只會看到那個打包過後的資源而且會覺得它擁有這些資源不用共享, 不是physical device上原本有的所有資源
- 例如isolate hostname, user/group id, process, network stack, 每一個資源就是一個namespace, 目前大約有8種namespace
- linux default process都會跑在預設的Namespace(一個default nsproxy, 裡面的element都指像default namespace)
- 可以透過systemcall來管理namespace(clone來產生新的namespace之類的)
- namespace實作為透過nsproxy這個c struct實作, nsproxy的element就是各個不同的namespace pointer(uts,ipc,pid…), 所以一個nsproxy是定義一組完整的namespace(file,memory,pid之類的)而不是單個namespace, 如果兩個process使用的namespace都相同,那就會指像同個nsproxy, 他們的task struct(PCB)裡面的namespace element 就會指向同個nsproxy struct
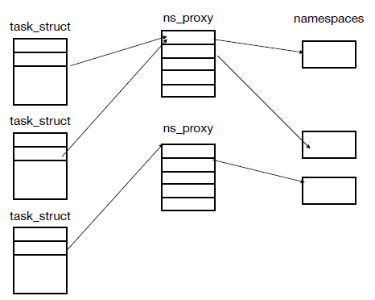
pid namespace
- pid isolation, 不同namespace裡可以有相同的pid.
- 也因為pid namespace的關係, 方便container migration, 只要做好pid mapping就可以輕易把現在container的Process id建立在另一套系統上
- pid namespace裡的init process(pid 1)就跟host系統上的pid1依樣做task management, 處理orphan process, 所以不可以被SIGKILL
- 實作如下, 每個namespace裡的process只能看到自己namespace裡的其他process, 然後他們會以為自己的pid是1,2,3, 但由Parent來看這些process的話, pid變成4-9這樣, 因此就是一個process自己看自己的pid跟parent看它的pid的值不同(概念上是呼叫clone創一個namespace跟process時, 在process裡面呼叫get_pid會得到namespace裡的pid值, 但parent呼叫child_pid時得到的會是parent space的namespace, 所以會看到另一個pid, 就是pid會因為呼叫get_pid的所在的namespace不同而回傳不同值), 然後child process呼叫get_ppid(parent pid)會得到0, 因為child pid看不到parent pid
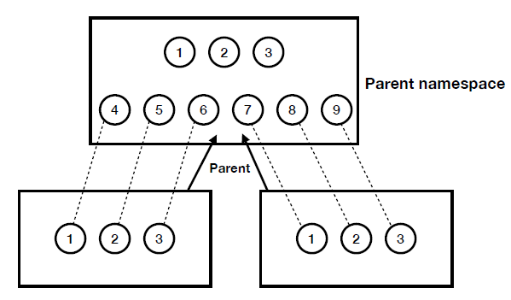
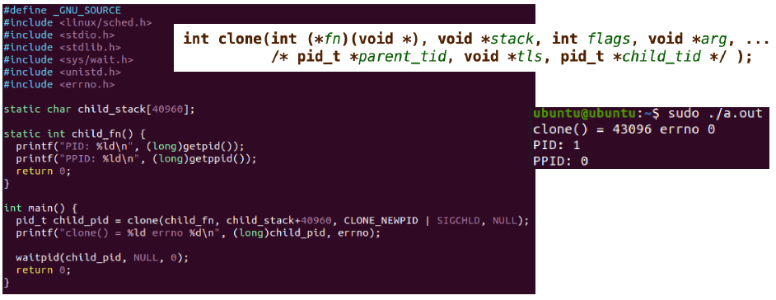
network namespace
每個namespace有自己的firewall rules, devices之類的, default新創立的network namespace只有loopback, 所以要自己加其他的device設置才能對外連.
k8s
幫助container能夠跑在cluster of nodes的環境下, 負責管理container跑在多台機器的環境下的部屬管理
功能
- Service Discovery, load-balancing
- container會有自己的DNS或ip address, 然後有load balance的功能
- storage orchestration
- k8s自動化讓資料能分配存在本地端或遠端的儲存空間
- Automatic rollouts/rollback
- 自動化batch建立刪除多個container
- Self-healing
- 對crach,exit的container會做restart, 或者k8s能夠幫忙做container的healthcheck
架構
- Control plan(k8s master): 開發者使用, 控制各個k8s node
- API server(kube-apiserver): 提供Api讓user可以用json格式發資料給他然後去做相對應處理, 控制在node跑的container
- etcd: 存資料的地方, 提供consistent high-available key-value store, 確保資料, 網路設定的保存, 舉例而言, 當某個node crash時, 就會透過etcd把資料restore/restart node
- scheduler: 安排pod跑的順序
- Controller Manager: 一堆的controller來控制整個系統的運行
- k8s node: 就是一台k8s機器, 上面可以跑多個container, container在k8s node裡跑在pod裡面
- kube-proxy: users可以透過k8s node上的proxy來使用container服務, proxy會把資料forward到特定的pod
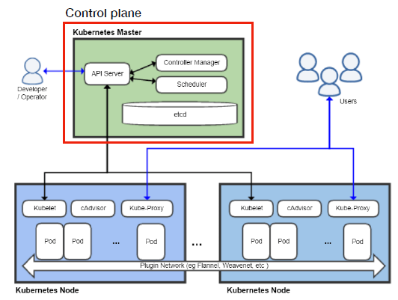
名詞
- kublet: 每個node有一個kublet(agent), 負責管理在該node上的pod(start/stop/maintain containers), 和跟container runtime做溝通
- pod: 一個pod可以有1-n個container, 是k8s裡面跑container的最小單位, 每個Pod有自己的id, ip address讓k8s能夠存取特定pod
- k8s proxy: 負責pod netowrk的設置, 管理cluster內跟cluster間的溝通
Pod實現
- 同個pod裡的container會有相同的Linux namespace, cgroups, IP address等等
- 同個pod裡的containers是用IPC或shared memory來做溝通
- 大部分情況是一個pod跑一個container, 部分時候是為了跑起一個application, 然後他有多個component時才需要跑在同個pod裡
Docker Swarm
- Docker自己提供的管理多個container的工具
- 跟k8s不同處為讓docker engine改為swarm mode來擔任managers或者workers, manager分配工作給worker, 每個manager, worker都跑docker engine
- 管理cluster state, schedule task, 提供一些API讓user能夠管理cluster
- manager node本身是有共識機制來產生single leader來統合整個任務調配, 如果leader掛了, 會在選一個新的leader
docker swarm流程
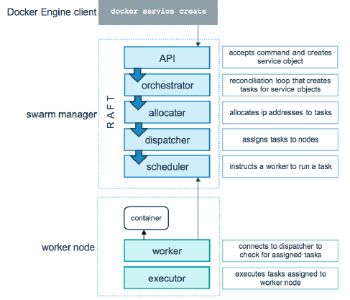
以建立一個service為例
- user透過docker cli打建立一個service的指令, 然後變成api傳給swarm manager
- swarm manager建立service object
- orchestrator把service切成多個tasks
- allocator建立好各個ip address給每個tasks
- dispatcher把task分配給各個node
- scheduler安排執行順序
- worker node跑起來 跑分配到的task
名詞解釋
- Node: 一個docker engine/instance, 在swarm mode裡, 依據功能分為manager或者worker node, 多個node可以跑在同台機器
- swarm: node clusters
- Service: 就是要跑的service, 可以選擇要跑的replicas, 會再透過docker內部把他切成多個task
- Task: 一個工作的單位從manager發包給worker nodes
Docker swarm vs k8s
- k8s比較複雜多元複雜的服務, 包括支援各種不同的container 要正確使用要有比較多的了解,
- 支援auto-scaling(自動化根據container需要的資源動態調配資源給container)
- swarm比較單純, 適用於small scale的case而且只支援docker類型的container
- 不支援auto-scaling(手動, 非自動化)
Serverless
Cloud provider負責server的安排, user不用去關心底部系統(infra, 環境, cpu, mem resource) 的管理, 只要關心application執行就好, 例如 amazon lambda, microsoft function, google cloud function
limitations
- deployed的function是stateless, 每次request就執行那個功能, cloud provider的設計不會cache住之前call的function的結果, 所以是stateless, 如果希望因為前幾次function call而改變這次function的執行狀況就不行
- 平行支援度問題, 一般平行化會用lock來存取data, 但serverless問題是每個function執行不會看到global state, 所以沒有一個global的人來告訴function是否該筆資料被lock住
- performance問題
- cold start(因為接收到demand才開啟服務執行, 這樣一個request執行速度慢, 像heroku那樣)
- cloud provide general的做scheduling, user不能根據自己的需求來做scheduling
- security問題
- 各種平台都能執行某種function, component也多, 例如就可以透過function的bug去偷取aws裡的credential
Container Security
- Container比較lightweight, 透過現有OS的功能來做isolation, 所以各個container是共用OS, 相對VM是由hardware支援的virtualization技術, 配合VMM來做資源分配. Container isolation效果較差較危險.
- OS kernel本身是一個很大很複雜的codebase(畢竟不是專門拿來做虛擬化, 還有一堆其他的用途功能), 這種狀況下就很容易有安全性的問題, 例如systemcall就有超多個, 如何限制container存取那些system call就是一個不輕鬆的工作
LightVM
一個work試圖結合VM跟container的優點, 在保持VM的isolation機制下, 能夠讓VM有container快速的boot time跟較少的資源使用(所以一次可以開數千台), 然後可以隨時pause,unpause轉換state
想法
在cloud上跑的VM或container很多時候只做某些特定的事情, 跑一個application而以之類的
- Unikernel:
- specialized, single address space的machine image, 裡面在跑一個library OS(LibOS)
- 只支援跑目標application需要的特定的kernel functionality, 所以unikernel目的只是要把application跑起來, 而不是general purpose, 所以需要load的東西就少很多
- 一個unikernel基本上就是用一個mirage runtime跟application code即可, 其他language runtime, OS kernel, library都不用, 所以整個stack變得很lightweight
- LibOS:
- 基本上就是輕量級的OS, 用來專們跑一個Application用
- user 跟kernel space沒做隔離
- OS kernel跟application跑在同個address space(沒有virtual address)
- 把OS服務變成library, 直接跟Application link起來, 所以可以想成裡面就是一個Application跟他需要的library/service包起來
- Performance很好, 沒有kernel layer, 所以Application能夠直接操作IO device, 不用透過kernel trap/context switch
- Portability問題, 因為不同IO device要用不同的library, 有kernel的話可以單純用system call剩下跟硬體互動就交給OS kernel做就好, 但現在變成要根據hardware包不同的library
因為unikernel和libOS的特性, 所以優點是保持vm的isolation而且變成lightweight, 只需針對特定的Application load需要的library即可. 缺點是portability變差, 因為換一個hardware可能需要的library會有些差異. 但對於在cloud上面的應用, 底層硬體會有VMM來做虛擬化, 這時unikernel的模式相對使用就很方便, 因為硬體部分交給VMM做好掌控, unikernel就不用太擔心底層硬體的問題.
缺點是 他是把Application跟OS kernel包在一起, 所以只要一更新Application, 修改某些feature, 就要把整包重新compile, 不像之前VM只要update Application就好, 而是整包都要一起Compile