Performance
04 October 2021
VM trap cost reduction
雖然提到一些hardware soltuion能夠減少VM_Exit的次數, 但問題是並不是所有hardware都support這些硬體虛擬化技術, 因此除了軟體的trap & emulate方式外, 可以考慮減少每次trap的overhead
Hypercall microbenchmark
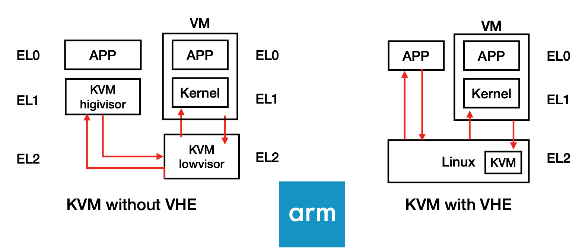
Arm在使用kvm hypercall時, 是由guest VM從el1發送hypercall request到KVM lowvisor(el2), el2設定好一些system register後在去到el1的kvm highvisor來做hypercall的handling
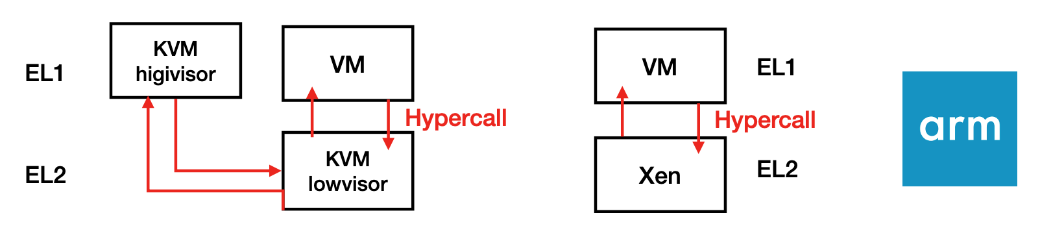
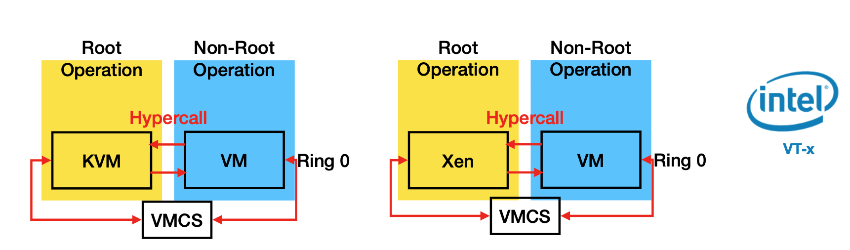
Xen則是Type 1 Hypervisor, Xen直接el2跑在baremetal上直接跟el1的guest VM做互動, KVM是type 2 hypervisor所以雖然要跑在hyp mode但是他必須有access to linux kernel, 因為很多功能都是依賴OS kernel來達成, 以Xen跑在Intel VT-x為例實際上打hypercall時只需要VM透過VMCS把現在state存起來 然後switch到Root Operation執行hypercall
Hypercall Performance:

圖為在不同架構下跑不同hypervisor時,發一個Hypercall所需的CPU cycle總數
在Arm環境中KVM遠比Xen慢的原因:
因為KVM是Type 2 hypervisor且使用Split mode的緣故, 所以一次的hypercall會需要很多的不同的mode switch, el1,el2之間不斷context switch, 不斷修改暫存器的值和不斷從記憶體讀另一個mode的state的值, Xen相對簡單就一個跑在Hyp mode的application
x86比ARM普遍而言慢的原因:
x86虛擬化技術是透過VMCS的方式存取目前的VM狀態然後從裡面讀另一個VM的資料放到hardware上來做VM switch, 所以每次VM_Exit時都需要把資料存到VMCS然後讀另一份資料出來, 包括system register之類的資料. Arm另一方面就是單純的el1 trap to el2, 只要把general purpose register資料存好restore好就好, 不用存太多其他額外的資料到記憶體
x86下KVM跟Xen結果差不多原因:
因為x86虛擬化的方式就是透過VMCS來做mode轉換和context switch到root operation ring0來做, 流程基本上差不多
IO處理效能
在IO處理方面, Xen處理速度遠比KVM慢很多, 原因是因為KVM本身用vhost ring buffer的形式傳送資料時VM_Exit會少很多且整個workflow單純, 就是guest VM到kvm host, kvm host跟linux kernel driver溝通. 但在Xen時guest VM的request要先到Xen, Xen再到Dom0, Dom0的driver在去跟硬體溝通, 流程變得比較長, 要notify然後switch到Xen, Dom0. 而且guest VM裡的資料也要copy出來到Xen.
Improvement (Arm VHE)
Arm VHE: Arm hardware優化讓整個Linux跑在EL2上, Arm提虛擬化額外的register供el2使用(把el1的暫存器導向到el2上),所以讓kernel用EL1暫存器來跑在EL2上, 這樣register數目就足夠讓Linux跑在EL2上