I/O Virtualization
06 October 2021
基本概念
- 基本概念就是VMM要能夠模擬各個不同的IO devices, 讓VM能夠感覺他真的擁有並使用這些device
- 提供一個fake interface讓VM能夠存取devices, Guest OS能夠去discover initialize然後運行這些virtual devices, 都要盡量用模擬的, 不能讓VM直接接觸到physical device, 會有安全性的問題
- 困難點: 每個IO device都有自己的spec (自己使用的register的方法, 有的沒的features, 這些VMM都需要有相對應的實作來support)
IO interposition
VMM中介IO device, 所有IO的query都傳給VMM處理,可能是硬體處理或軟體模擬, 反正就是像trap & emulate, 讓VM感覺他真的擁有device, 所以VM的Device driver的call是傳給VMM做處理, 透過軟體的方式
特色
- 讓Hypervisor 可以封裝VM IO device的state(畢竟是VMM用software模擬的)
- VM Migration & portability: 就算underlying的machine改變, 要把VM轉移到另一個有不同IO device的machine, 因為整個IO device基本上是靠VMM模擬的, 所以可以無痛的轉移. 而且是由VMM負責模擬, 所以把他跟底部physical device isolate.
- software模擬可以讓Virtual IO device更容易加更多不同的features(e.g. disk自動備份之類的, 或者客製化的cache機制, VMM實作)
Physical IO
OS透過firmware(bios, bootloader)或者device tree files(ARM)來得知目前有哪些device driver跟device, physical IO通常裝置都是會在特定的port或address.
所有driver都是在CPU上跑, Hardware要提供機制讓CPU能夠去跟各個physical IO元件溝通, 例如PCIE通道就是CPU跟hardware溝通的接口 (VMM如果要虛擬化模擬,也就是要模擬PCIE的傳輸,讓guest OS能夠感覺跟真的IO device在溝通)
CPU跟IO device溝通的方法
MMIO(Memory-mapped IO) / PIO(Port-mapped IO)
- IO Device都會被assign到一個特定的記憶體或ports
- CPU提供
- PIO x86提供IN,OUT的指令來做IO資料存取, 基本上也是去存取某個類似的記憶體地址(稱為port,是一種只有16bit的address), 但ARM沒有
- PIO instruction是privileged instruction(只有system mode CPU能執行, 所以VMM對於這些指令在於VM執行要讓他trap)
- MMIO就是利用CPU的記憶體存取的指令(load,store)去讀取特定的IO address
DMA(Direct Memory Access)
使用MMIO/PIO的方法對於IO資料交換有時候太慢, 而且整套指令CPU要幫忙協助記憶體的存取. 因此DMA允許IO device直接去存取Memory上的資料而不需要CPU的協助, IO device存取資料時CPU能夠繼續做他的事. 舉例而言, 網路封包是CPU把他包好後放在Memory, 這時網卡就可以透過DMA去讀取記憶體中的封包然後真的把他在segment或者送出去. DMA通常在IO device做完後會interrupt來通知CPU, 然後CPU就可以unlock這塊memory之類的讓其他人能存取或處理.
Interrupt (IRQ)
Hardware發送async event給CPU, 所以發完interrupt, IO device還能夠繼續做他的事. Interrupt都會有自己的編號, OS, VMM對於不同的Interrupt都會有一個特定的handler來處理他. 例如x86有Interrupt Descriptor Table(IDT)來map interrupt號碼跟對應的Handler. Device driver通常會提供自己對應的interrupt handler, 所以在setup device driver時會在IDT table上註冊一個新的entry.
IPI
Inter-processor interrupts, CPU發interrupt給另一個CPU
Interrupt Controller
上述雖然說會把interrupt發送給CPU, 但實際上會先傳到Controller這個在傳給CPU. Interrupt Controller是一個hardware component負責接收各個device傳過來的interrupt訊息(算是集中到這裡), controller會把interupt再送到CPU. OS, VMM可以管控這個controller, 例如enabled/disabled interrupt(atomic operation就是把controller disabled做的), 或者告訴hardware intterrupt handling完成
Local Advanced Programmable Interrupt Controller(LAPIC): x86上的Interrupt Controller,每個CPU都會有一個這個component, 裡面實作就是很多暫存器, CPU可以透過去存取這些暫存器完成各種interrupt的傳遞. 例如CPU可以透過MMIO intstruction來設定上面管理IPI的暫存器, 然後CPU就可以發interrupt到另一個CPU. 新的x86上的Interrupt Controller變成x2APIC, 他是利用MSR(model specific register)來執行.
Ring Buffer
現在的device都能有很高的throughput, pcie通道允許非常大量的資料傳遞, 所以用ring buffer來做大量的資料傳輸.
Ring Buffer是一個Device Driver跟CPU之間的shared memory/array, 兩者都能直接對這塊記憶體操控, 但這個東西比較像是一個look-up table, 每個entry紀錄要去哪裡讀多少資料. Ring Buffer有很多的entry(又叫DMA descriptor). Descriptor包含size, address,分別記錄要去physical address讀或寫size大小的資料. 舉例來講NIC就有RX, TX兩個的ring buffer分別紀錄讀和寫的address的table.
OS device driver會allocate一塊Memory給ring buffer並且做好設定, 包括ring buffer的base address跟buffer size, 讓device知道範圍和有多少空間何時會滿. HEAD紀錄device把資料處理到哪裡, 由device來移動, device處理完一筆資料就往上移, Tail紀錄OS放了哪些資料要device處理, 每新放一筆資料就要把TAIL往上移.
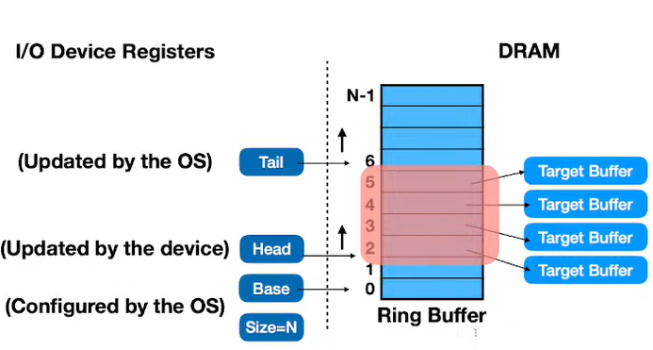
Bursted IO requests
Devices會發interrupt告訴OS ring buffer的狀況(例如buffer滿了,要device driver清空, 或者資料ready了要OS來讀), 但每次device讀寫都要發一次interrupt overhead太大, 所以有bursted IO requests, 就是把數個requests集結再一起發一個interrupt就好.
PCIe
一個Unfied的介面讓各個device能接到主機板上(網卡,GPU,音效卡….).
裡面有per device configuration space
- 提供vendor, device ID給Hypervisor來找到對應的device driver告訴他們怎麼initialize或處理這個device
- 包含Base Address Registers(BAR), device的地址,MMIO才知道要去哪裡跟device互動
PCIe一個特色是可以更有效率發送Interrupt給CPU, 可以透過Message Signaled Interrupt(MSI)發送interrupt到LAPIC, 會比使用IO APIC的方式快
IO Virtualization techniques
- 要讓Guest OS相信他有全權掌控IO device(但當然實際上沒有)
- 不能直接讓VM存取physical device(不然可能會影響到VMM和其他VM)
- VMM要管控physical IO device讓所有VM和自己使用
- 主要分成三種方法: IO Emulation, IO Paravirtualization, IO Device Assignment, 有些做法會需要Hardware support
IO Emulation
VMM透過IO interposition的方法模擬出Virtual Device和介面跟VM溝通, 透過trap & emulate trap MMIO, PIO operation到VMM. trap的作法是把MMIO, 要access的memory在NPT unmap, 這樣mmio存取device記憶體就會trigger Page fault到VMM, VMM再來看是因為存取device IO還是就單純是非法記憶體存取. PIO則是可以在VMCS設定每次呼叫就trap, 缺點就是page granularity就是4K, 有點大. VMM除了模擬hardware行為, 也要模擬hardware發送interrupt給guestOS, 例如r/w complete之類的
Interrupt流程
- Program execute時, hardware發起interrupt這個signal給CPU
- Hardware把CPU從user mode改成kernel mode, 把interrupt disabled(在interrupt controller, 避免在handle時又發生interrupt), OS kernel把目前process的資料存起來(register, PC…), 把PC移到interrupt handler
- OS kernel context switch到interrupt handler(載入interrupt handler的register等等process資料), 結束後再switch回原本程式
VMM要做的就是模擬這些CPU system mode的切換, context switch的部分
Interrupt Injection
VMM software soltuion to interrupt simulation.
hardware發送interrupt不能直接給VM處理, 這樣VMM沒有辦法做VM的全權管控, 例如Interrupt跑完Program counter跳掉或者VM直接掛掉, 這些事情VMM會變得沒辦法插手. 因此Interrupt Injection的困難點就在於要保持VMM在這種情況下仍能掌控VM. 而且VMM也要模擬hardware status(向上面提到的interrupt也要注意register的儲存, interrupt controller的enable/disable)
所以變成Hardware發送interrupt會被trap到VMM, VMM再告知VM有虛擬的interrupt
Software-based approach
VMM攔截hardware interrupt然後在發送interrupt到VM, 缺點是會很沒效率, 跑一次流程可能會發生很多次context switch
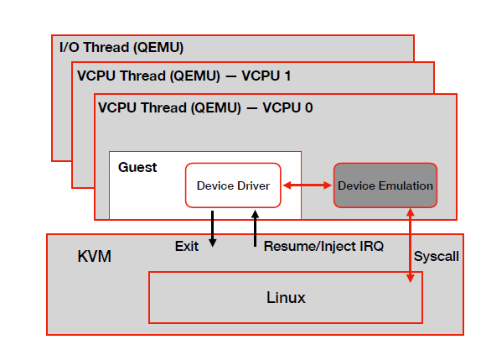
IO Emulation in KVM(System VMM)
KVM跑在kernel mode, 然後是透過user mode的application(QEMU)來完成虛擬化, QEMU會有一個device emulation的程式用software形式模擬device, QEMU會為每個VM的vCPU, 每個IO device建立個別的thread, IO thread負責處理背景工作(network不斷收送封包之類的IO). 整個software-based approach流程以下圖為例
- guest Device driver存取Memory(MMIO,PIO)沒有map所以trap到KVM
- KVM處理然後switch到qemu的device emulation, emulation會透過system call跟KVM做溝通, 最後把模擬結果傳回給device driver
- KVM處理完後會Resume或Inject IRQ給VM讓他能夠繼續執行, 接收IO傳來的資料(Interrupt handler的程式負責收資料)
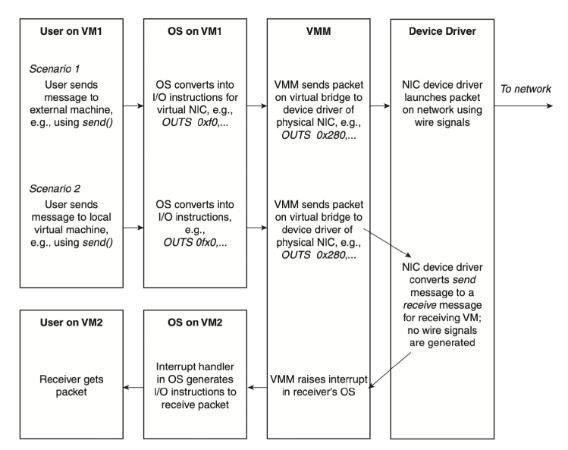
舉例而言如下下圖, VM裡的process要送封包, 所以OS要把封包資料寫到特定記憶體讓NIC存取, NIC要存取資源被trap到KVM, 然後QEMU的device emulation會跟KVM溝通, KVM會再跟physical NIC溝通把結果傳回給device emulation, 這種作法問題點就是會有非常多的CPU mode switch.
IO Paravirtualization
IO Emulation performance overhead太大(不斷cpu user/kernel mode切換), 另一個問題是IO trap的機制在於unmap IO memory, 但page table一個page 4K, 很多device的暫存器通常都會在同個page, 有些暫存器其實沒必要trap, 但因為放在同個page裡, 所以就不能做這種優化.
- IO裝置做Paravirtualization
- Portability降低, 一個VMM的driver不能在其他VMM上跑, driver本身也要能支援不同OS version
- 概念是Guest VM implement/import自己修改的device driver, 然後透過對應的qemu device interface作互動, 然後真的需要access physical device時才trap到KVM
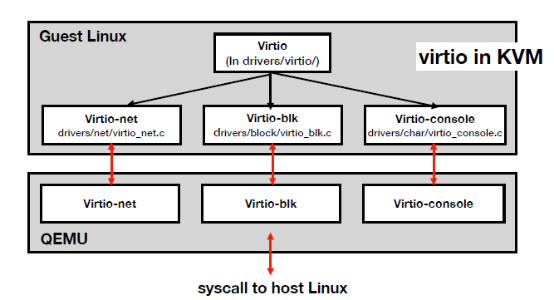
Virtio
- Guest跟host IO溝通的interface, 支援network IO, block IO, console IO(serial port)
- Guest要提供自己的driver(paravirtualization), 所以Guest要自己的console, block, network IO driver, 然後qemu就會有對應的介面能夠和driver做溝通
- 有virtqueue(一種ring buffer)提升效能,VMM,VM能夠透過ring buffer交換資料
- 而且最重要的是能夠降低interrupt跟VM_EXIT的次數來提升效能, VM會把data 加一些Descriptor放到virtqueue, VMM, VM可以透過這樣來存取data.
- virtqueue也提供一些hypercall指令讓VM呼叫來通知VMM (e.g. virtqueue_kick)
- virtqueue也支援不同模式(no_interrupt,no_notify), VM可以告訴VMM目前virtqueue狀態, 降低VM_EXIT發生的次數.
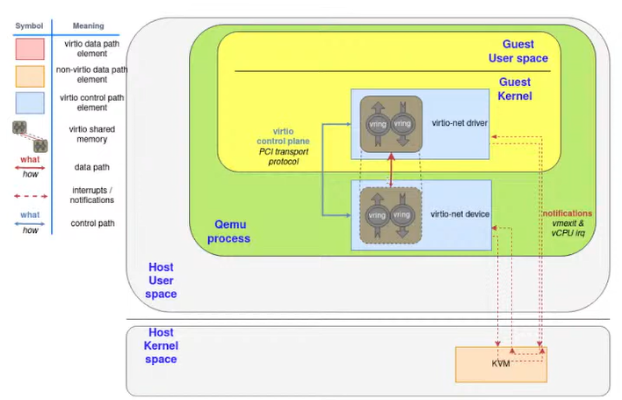
Guest driver 跟Qemu的device interface都能存取一塊shared memory,傳遞或存取資料不用執行那個acess指令時還要從guest VM的 io driver trap到 kvm然後再到qemu的emulated device來處理, 而是either guest VM或者qemu device能夠直接存取那塊shared memory來得到值, 例如emulated device已經把資料放到shared memory, guest VM要取得device資料時就不用trap到kvm在從kvm跑到qemu device拿資料. 其中以下圖為例, device的control, data plan都在qemu裡, 所以data plan存取就用那塊shared memory, 不用exit. 但control plan存取如果真的要拿到physical device的值就要trap到kvm, 然後一樣qemu透過system call跟kvm溝通, 最後結果在傳回給qemu的virtio-net device. 這樣就能減少VM_EXIT的次數
IO的data plane & Control plane:
- Data plane: data傳輸方法(PCI)
- Control plane: 控制IO device執行的config
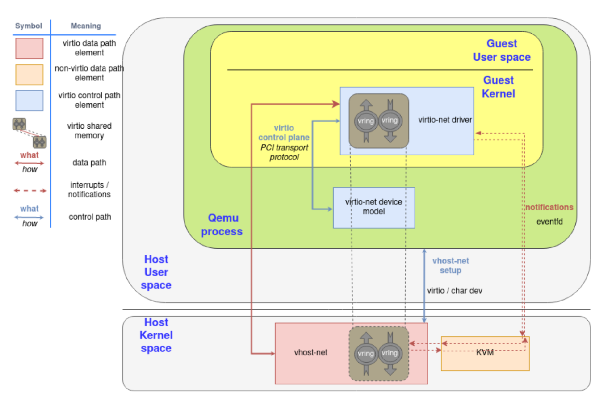
v-host net
另外更optimized的方式是把data plane的qemu shared memory移到kernel裡面. 所以把data plane移到kernel space, 好處是vhost-net可以直接access kernel space的physical device driver. 然後shared memory變成從kernel space memory對應到qemu裡的guest VM kernel裡, 這樣又可以減少很多的trap.
IO Device Assignment (Passthrough)
Hardware solution, 前面兩個Software-based solution就是利用軟體trap到VMM的方式來handle IO operation, 缺點當然是這樣會有效能問題. 所以這個方法是hardware solution, 提供VM直接access physical device的方法,
缺點
- 會有security issue(vm直接搞physical device, 不管是讀VMM資料或者control VMM)
- 會有scalability問題, 有些devices可能會限制connect數量, 100台VM都直接存取某個Device IO可能會有問題
優點
VM可以直接用自己的OS上的device driver來連接Physical device, 不用額外實做模擬的device. 可以大幅減少VM_EXIT跳到VMM處理的狀況, 大幅提升效率.
IOMMU
- 幫助device passthrough的security
- MMU: 管控process能access的Memory範圍, 透過Page table
- IOMMU就是類似機制, device只能存取特定範圍的Memory (intel: VT-d, AMD: IOvirt, ARM: SMMU)
- 把IO virtual address(IOVA)轉換成hpa
- IOMMU也會walk page table, 所以DMA實得到的address會讓IOMMU去walk page table
- IOMMU也有TLB cache, 盡量不要發生Page fault, 因為IO通常比較緊急, 例如封包等太久就data loss或connection failed之類的
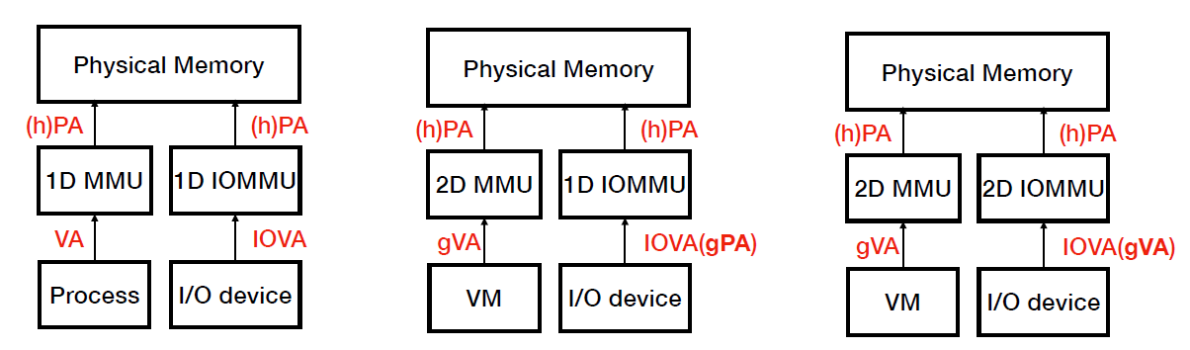
address space問題:
因為記憶體虛擬化關係, VM能夠access的只有gpa, 而這個跟實際上的hpa並不相同, VM沒有辦法直接access physical address
IOMMU for VT-d
IOMMU在intel VT-d的實作上包含DMAR, IR這兩個部份
- DMA mapping engine(DMAR): address retranslation(page table, IOVA->gpa->hpa)
- Interrupt remapping engine(IR): VM可能會有自己的Interrupt number, number不見得跟host上一樣.
- VT-D的page table也是Multi-layer, 要walk數個page table才走到hpa
- VMM要設定讓VM透過DMA access memory時都要到IOMMU轉換, VMM透過IOMMU page table mapping來限制記憶體存取權限然後把gpa轉成hpa
- VMM在IOMMU的page table一開始就會把所有address建立好,避免page fault(所以IOMMU table並沒有demand paging的機制), 因為IO通常資料比較緊急, page fault可能會導致IO data loss
下圖做一個Memory access, IO memory access在有無VM的狀況下的流程,1D代表一層,2D代表兩層. 最左邊圖是沒有VM的狀況, 只有一層page table直接map到physical memory. 中間圖代表IOMMU VM直接把IO device address從gpa map到hpa, 是可以防止device access 不該存取的hpa, 但問題點是device可以access VM的任意memory(因為直接map到hpa), 所以本身IOMMU也要兩層, 讓device在VM裡面也不能隨便讀取hpa.
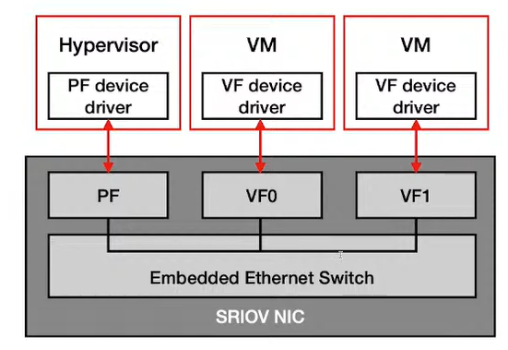
SRIOV
- Hardware 通常只能support一定數量的Physical devices, 當VM多時,硬體就沒辦法support這麼多VM instance存取IO
- Single Root IO(SRIOV)幫助scalability(讓hardware能夠support很多VM,讓很多VM有直接access hardware的感覺, self-virtualize)
- 延伸PCIe, SRIOV device能夠讓software看起來像是這個Device有很多個instance, 所以每個VM instance都能夠直接存取的感覺, 所以SRIOV device是hardware level的Multiplexing, 有點像vCPU的概念
- VMM跟SRIOV device透過Physical Function做溝通, VM透過Virtual Function跟physical device做溝通, 所以VM跟Virtual Function能夠用DMA做溝通, 所以VM做某些physical devie的access時不用VMM介入
- Physical Function(PF): 真實在hardware上跑的function, PCIe function, 有自己的configuration space
- Virtual Function(VF): Physical Function透過hardware虛擬話技術把它變成多個Virtual Function, VM透過Virtual Function操控device. Host software(OS,VMM)可以allocate, deallocate, configure VF. 功能相對PF侷限,因為要避免VF影響到Physical interface, 例如VF不會有power management這些功能把Device shut down.
Interrupt handling
IOMMU和SRIOV等等硬體solution雖然貴而且不是每個硬體都有, 但是已經能大幅減少VM_Exit的次數 提升IO access的效率. 但問題是Interrupt的VM_Exit次數仍居高不下
VT-x Interrupt Support
hardware IO virtualization能夠減少VM_EXIT次數, 但interrupt仍然是整個流程的一個overhead
VMCS存guest的Interrupt Descriptor Table Register(IDTR), 所以context switch到VM時就會連同這個一起load進去. VMM會把VMCS裡的external-interrupt exiting bit設成1, 所有physical interrupt(Hardware issued)會先trap到VMM,VMM在用virtual interrupt給VM(確保VMM有VM的full control)
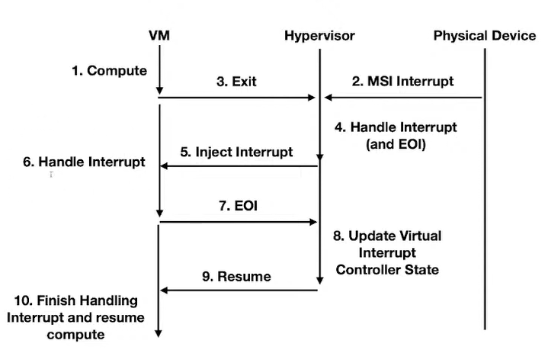
在intel VT-x下的VM interrupt handle流程如下圖:
在VM執行時假設Physical Device發了一個interrupt, VM會先VM_EXIT到VMM來handle這個interrupt, VMM做完後會發EOI告訴hardware Exception處理完了,然後在inject interrupt(virtual interrupt)給VM, VM做完後一樣會發EOI給VMM(這裡又要VM_EXIT), VMM就會根據VM的EOI來update hardware state和Virtual Interrupt Controller state, 最後再回VM繼續執行. 整個流程有兩個VM_EXIT
EOI register: intel新版的interrupt controller(x2APIC)提供這個暫存器讓VM直接對這個register做修改來表示是否處理完Interrupt(EOI), 但本身修改這個register需要使用MMIO的privilege instruction, 所以修改EOI register會有trap的問題
上述流程一個hardware interrupt要兩次VM_Exit cost太高, 所以X2APIC就是可以讓VM透過MSR來修改EOI register, VMM可以透過VMCS來設定執行MSR時是否要trap
Exitless Interrupts(ELI): trap到VMM的interrupt也減少(第一次VM_EXIT, interrupt要傳給VMM保證VMM可以管控VM). 這個方法讓VM直接handle passthrough physical device的interrupt而不用先trap到VMM做處理在發virtual interrupt. 相關的實作如Intel VT-d posted interrupt, AMD Advanced Virtual Interrupt Controller(AVIC), 可以在根據功能分為CPU posted interrupt, IOMMU posted interrupt .
總結
| Virtual IO model | Emulation | Paravirtualization | Device Assignment |
|---|---|---|---|
| Portable(no host-specific software) | Yes | No | Yes |
| Interposition | Yes | Yes | No |
| Performance | Worst | Better | Best |
VMM Implementations
歷史
- 早期是single-core的大型電腦為了能夠share resource給multi-users, 所以有VMM來管理各個使用者的使用(Resrouce management & Isolation)
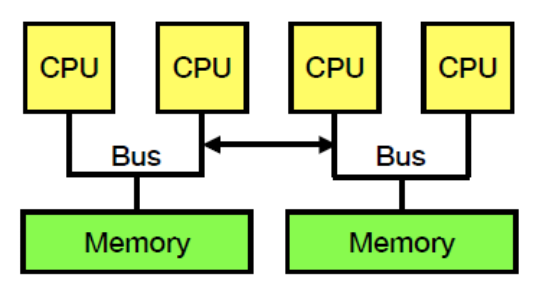
- Multi-core的環境出現, 早期OS的設計不容易在這種環境下很好的運行(早期single-core可能比較沒有lock之類的問題或者Numa問題, non-uniform memory access, UMA代表每個CPU存取記憶體的bandwidth,latency都一樣,或者共用Bus, 這樣會有多個CPU競爭相同一塊Memory access的performance問題).
NUMA: 把Memory分區塊分給個別CPU, CPU access自己local memory比較快, 但access其他地方memory比較慢, 這樣CPU就可以把自己需要常用的資料放在local memory端, 不常用的放在遠的Memory區塊, 更有效率的利用記憶體跟Bus的傳輸. 在multiprocessor狀況下, UMA(Uniformed memory access)會導致如果多個CPU要使用同塊記憶體的話為了確保sync問題會要用lock, 一次只能一個CPU做讀寫, 那這樣勢必影響效能.
Disco
在Multi-core(Multi-threaded, shared memory),NUMA狀況下再MIPS運行的一個VMM(讓MIPS的privlege instruction會trap), Physical memory support Numa, 跑不同OS, 更好的VM fault containment. 也提供SCSI virtual disk的abstraction給VM, 或者模擬Network devices給VM, Disco VMM類似Gateway能夠幫助各個VM透過Virtual NIC互相傳遞訊息.
基本上所有虛擬化問題都有軟體方法解決, Virtual CPU就是用Data structure存CPU的狀態, VM OS kernel的exception(page fault, system call…)都是先傳給Disco再做處理, Interrupt也是Disco 先處理再inject給VM. 關於Memory的虛擬化, MIPS的架構Hardware可以透過TLB來做virtual memory到physical memory的translation. Guest VM的TLB會把gva轉成gpa, gpa再透過Disco上的pmap這個自己記錄的data structure轉成hpa, Disco的TLB則是存gva到hpa. Disco是把VM每次的Memory access都trap到Disco的pmap上做更新, 所以只要maintain pmap即可, 而不用像SPT要maintain兩個table(SPT跟GPT).
Disco, Xen都是Type I hypervisor(bare-metal hypervisor), 直接跑在硬體上
Challenges:
- Trap & Emulate (因為Disco那時還沒有Hardware Support), 但Disco提供一些Extension來加速某些常見的Kernel operation, 像是把某些Sensitive instruction替換成load/store, 就不用trap了(Paravirtualization, 把某些CPU instruction對於暫存器的存取改成memory load/store)
- Handle VM IO access
- Resource Management: VMM沒辦法像OS直接handle, 看到各個process(VM space process VMM看不到)
- Communication & Sharing: 不同VM file sharing或者Communicate(Disco support shared Memory-based IPC)
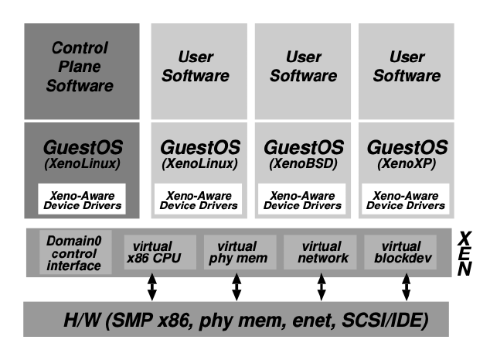
Xen
另一種VMM實作, Type-1 Hypervisor(跑在bare metal上), 一樣有很多Software-based的方法(那時沒有硬體虛擬化support), 目標再提升Security, performance的部分和更多的functionality(那時OS有更多功能,XP之類的)
Disco, VMWare ESX, modern VMM都是Full Virtualization, 跑VM都不用修改guest OS就可以架起來, Xen是Paravirtualization, guest OS需要修改VMM才能跑起來VM, Xen提供一個similar but not identical的hardware interface給VM用(改良版的hardware interface(? 提高虛擬化performance).
VM可以跟Xen註冊自己的Exception handler, 讓VM的Exception, interrupt能夠更快處理. 記憶體方面有support x86 segment跟paging, Xen直接提供API給guest VM來修改Page Table(不是NPT或者SPT), 依樣這種作法只要再VMM maintain一套page table就好, VM要修改時就呼叫API來教VMM幫忙修改Page Table. Device IO提供Paravirtualize的interface, 透過類似ring buffer來async的傳遞資料來減少VM_Exit次數.
Domain0 VM是管理層面較高的VM, admin可以透過Domain0 VM使用Hypercalls(跟Xen溝通的API)去跟Xen溝通來控制其他guest VM, 而溝通方式是用event方式(可以async傳遞資料). Xen Dom0的kernel有一個Native Driver跟Physical IO做互動達到IO虛擬化
記憶體實作方式基本上是用static partition, VM分到一塊記憶體然後自己在這塊記憶體上create page table, 然後每次修改page table都會發hypercall到Xen讓VMM來修改PT(透過guest OS hypercall request), 但因為每次修改都要發hypercall代價有點高, 所以會使用batch update的方式來做(一次hypercall update PT實際上裡面有複數個PT update的指令)
在有hardware support的狀況下, Xen是跑在Ring 0(最底層, 因為他deisgn是不需要hardware support, 但要掌握hardware resource, 就要跑在Ring0, 然後Guest OS跑在Ring 1, Gueset App跑在Ring 3)