Virtual Machine Intro
07 October 2021
Why Virtualization
- Secuirty
- 虛擬化可以讓不同的process隔離,不會讓不同的process互相影響,當一個Process被compromise時也不會影響到其他process
- Performance
- 虛擬化可以更好分配硬體資源給各個process, 例如各個virtual machine可以決定我要分配到幾個virtual cpu, 所以需要資源多的可以分配到更多資源, 需要資源少的會分配到較少資源, 但他們自己看到的都是自己有很多資源, 例如Virtual Memory看起來很大, 但真正使用到的才會有mapping, 其他valid bit=0或者map到disk.
- 可以把硬體資源做abstraction, 把他切成更多份分給需要的process(例如virtual memory會比memory大的原因之一就是它處理好memory,swap,disk之類的mapping, 能夠很好使用不同storage的硬體)
- 某方面像OS, 可以更簡單的做到scheduling跟resource sharing/abstraction和管控
- Flexibility & Portability
- 虛擬化可以讓一個電腦或伺服器支援各種不同的架構(x86,arm…),
- 可以方便讓編譯過後的可以在各個不同的機器上跑而不用重新編譯或link(e.g. Java JVM)
- Encapsulation
- 可以把OS snapshot,需要的時候可以簡單把整個OS state搬到另一個實體機器上
Virtualization 重點
- state mapping: 不同架構可能有的資源跟模式不一樣(例如x86, arm兩個架構的暫存器就不同), 因此要有各種state的mapping
- Emulation: ISA的mapping, 每個對應的指令要能夠map到另一個環境的指令且執行結果要一樣
Virtual Machine種類
- User-level ISA: 就是一般常見的ISA
- System-level ISA: 包括一些scheduling, paging, memory allocation的ISA
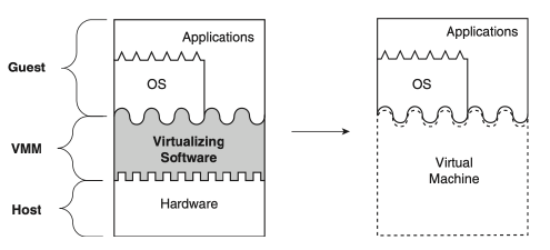
- System VM
- system level VM, 基本上不用OS也能跑, 實作在ISA interface(user-level,system-level ISA)
- 相對於process VM, 他會提供一個完整的環境(support OS kernel, virtual Hardware), 可以在上面跑一個完整OS kernel
- 例如vmware, virtualbox
- 虛擬化種類分為: Full Virtualization 和 paraVirtualization
- Full virtualization: OS可以直接跑在VMM上(iso檔之類的, 不用修改任何東西)
- Para Virtualization: guest OS要implement自己的device driver或者一些功能才能夠跟VMM做那部份的整合跟串接
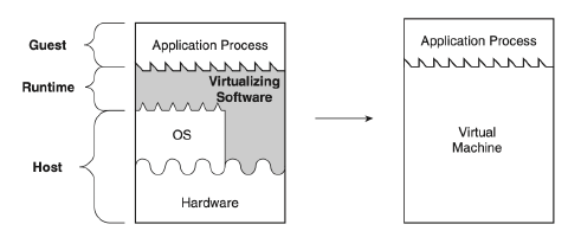
- Process VM:
- user-level VM,基本上是跑在OS上的, 所以她的implement主要會是利用user-level ISA或者OS system call來存取硬體資源
- 基本上很大部分他是一個OS上的process
- 例如Apple Rosetta, 把x86的架構的code轉成arm-based, java JVM定義一串自己的virtual ISA,然後串接OS kernel或hardware,bytecode就是符合這個virtual ISA的程式, 其中Rosetta, jvm都是user-space的virtualization,所以Rosetta會有很多Privileged指令沒辦法執行,導致很多程式不見得能夠在Rosetta上運作
Process VM
System VM
VMM
VMM Design principle:
- Equivalance: virtual HW interface, VM abstraction, VM的行為要跟跑在真實hardware上一樣
- Performance: 多個VM跑要能夠有效運用硬體資源
- Full Control: 要能夠完整掌握Hardware這樣才能isolate VM達到安全效果
VMM 種類:
- Type 1 Hypervisor: VMM直接跑在physical hardware上, 基本上兼具OS的功能, 要做scheduling, machine bootstrapping(bring up VM), 資源分配. 他某方面來說也算是一種OS kernel, 可以在grub時選擇要boot Hypervisor (Disco, Xen, Hyper-V, VMWare ESXi)
- Type 2 Hypervisor: 跑在Host OS上,可以使用OS的library, 因為有完整的OS support和flexibility,所以能做到的虛擬化相對比Type 1多(Type 1直接跑在hardware上,不容易很好的support各種hardware features) (KVM)
CPU Virtualization
- 虛擬化CPU資源, 一台電腦可能會有多個CPU,每個CPU又有自己的register
- 虛擬化ISA, 能夠運行不同的CPU架構
- VMM基本上在這裡扮演OS的角色, 產生virtual CPU然後做Context switch, resource allocation給VM, 所以VMM會負責各VM的Context Switch(設定timer interrupt VM然後存state, 讀下一個VM state出來換他執行), 而各VM則是可以正常使用那些Virtual CPU,像他們使用實體正常CPU一樣
ISA 虛擬化
例如我希望在x86的架構上裝一個VMM讓他可以跑非x86的cpu architecture的程式, 這部分就要做ISA虛擬化跟emulation(即把arm上的ISA map到x86的ISA,所以每個指令會有對應的x86執行方式), 但單純這樣不work,因為兩個原因
- arm, x86有不同的state, register type,所以register部分也要做mapping才能夠完整的執行指令
- Privileged instruction有些CPU指令是system mode, 一來是VMM要判斷該VM有沒有權限這麼做, 二來是就算能那麼做, 要如何保證isolation, 不影響其他VM, VMM的執行. 舉例來說, PSW, CR3, IDTR之類的指令屬於System ISA,會影響paging table, interrupt descriptor甚至scheduling的狀況, 如果這些register, 資源是VM, VMM共享,或者作用在physical CPU上, VM跑這些指令會影響到VMM.
因此VM有一個條件是他不能修改會影響到其他人的hardware資源, 直覺想法是VMM跑在CPU system mode,然後VM都跑在CPU user mode
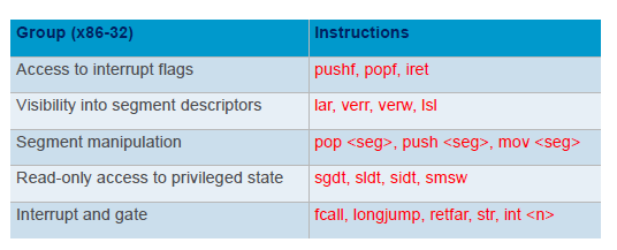
Instruction Set Properties
- Privileged Instruction: 這些指令如果在user mode執行會trap, system mode不會(e.g CPU halt指令, LPSW,SPT(設定CPU timer之類的)
- Control Sensitive Instruction: 會改變sytem config, resources的指令(SPT, LPSW,CR3)
- Behavioral Sensitive Instruction: 同樣指令在不同config下會有不同行為(例如在system mode可以正常跑但usermode會自動變nop)
- Sensitive instruction: 跟hardware互動的指令
ISA Virtualizability的規範
ISA能夠被虛擬化有以下條件
- 如果sensitive instruction是privileged instruction的subset, 則可以建立VMM (ISA is virtualizable, 因為所有會影響hardware的instruction都會trap到system mode), 對non-privileged instruction,可以直接虛擬化執行, privilege instruction則利用trap-and-emulate來執行
- 如果ISA是可以虛擬化的,而且沒有time dependences的問題則可以nested-virtualize(虛擬機裡跑虛擬機)
Trap-and-emulate
因為VM是跑在user-mode, 基本上就是privileged instruction執行時就會trap並把資訊送給VMM, VMM判斷VM是否有指令來決定要怎麼做, 如果他是會修改hardware的資訊時(例如physical CPU register或者某些OS table時), 就用VMM的memory存這些資訊讓VM修改, VM會以為他修改了physical CPU register,實際上是修改到VMM memory, 所以VMM memory就會負責要模擬這些修改後的hardware特性
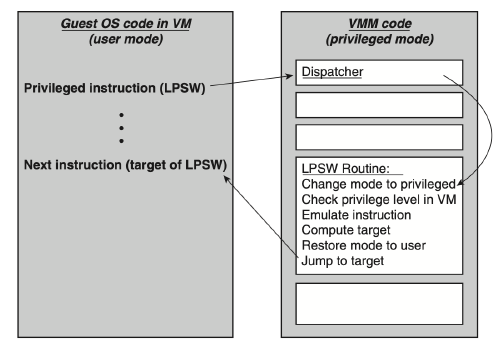
Problem with Trap-and-Emulate
Trap-and-emulate有兩個大問題:
- critical instruction(sensitive instructions that do not trap)在user-mode執行時不會trap
- 效率問題, 如果今天是模擬一個OS-kernel, 會有非常多的system instruction(e.g. context switch…), 總不能每次都trap and emulate(trap and emulate都是memory access).
Critical Instruction範例:
解法:
- Full virtualization: 做live patching或者執行前做binary translation, 但很明顯很難, 一來很多OS(windows)沒開源, 很多指令的修改也是case-by-case, live patching難度高
- Paravirtualization: 可以acces software source code, 改VM裡面software source code
基本上就是找code裡面critical instruction把他轉成trap的instruction
Hardware virtualization
把虛擬化的解法從軟體移到硬體. 好處是他能夠更完整更簡單的support VM虛擬化的部分,不用擔心某些critical instruction or sensitive instruction影響到其他VM或者VMM, 更不用做也不用trap-and-emulate. 這些都由hardware來處理. 因此system-mode的VM也能夠很好的運行.
Intel VT-x
又叫VMX(Virtual Machine Extension), 大概念是把operation分成root,non-root. non-root users不能跑root operation.
把CPU分成4個Ring, Ring0是kernel mode, Ring3是user mode, 任何VM都可以跑在任何一個ring, 但基本上跑在這些ring都是虛擬化後的, 所以VM可以跑在Ring0, 但其實是在虛擬環境, 所以不會影響其他在Ring0的Process, 而VM是non-root operation, 不會對實體硬體有太多修改, 也不能執行root operation.
把使用者分為root, non-root, VMM是root(full hardware control), VM是non-root(no full hardware control),但他們彼此都會有4個ring的access. VT-x提供一套root/non-root兩個operation context switch的方法
VMCS (Virtual Machine Control System)
Intel VT-x的虛擬化技術
- In memory資料結構(每個CPU都有一塊這個資料), VM state(CPU資料,register)
- Hardware會去存取這個資料去讀取CPU state讀進Hardware
- Fine-grain control VM execution(trap CPU operation,記憶體讀取Access control)
- 紀錄VM exit information(exception message之類的)
流程舉例: VMX存VMM state到VMCS裡,再從裡面讀取另一個VM state讀進hardware內(VMM context switch到VM), VMX也有提供一些指令來做這些事(init vm, load/store vm to VMCS), VMCLEAR, VMPTRLD(load VMCS to CPU),VMREAD,VMWRITE(access VMCS field), 或者VMLAUNCH, VMRESUME, VMXON之類的更方便的instruction.
Arm VE(Virtualization Extension)
- 在熟悉的kernel/system mode(EL1)跟user mode(EL0)外再加一個CPU mode(EL2)跑VMM
- EL0通常跑Arm application, EL1跑Arm的OS
- EL2在EL1和Hardware層之間, 比EL1有更高的執行權限, 有自己的system resgisters和address space, 因此VMM透過EL2 registers可以管控Guest OS, VM(EL1)行為
- VE不用做Context Switch, 所以要VM, context switch的話就要透過Software來做到(所以VMM要做VM的Context switch)
- 利用ttbr(相當於intel上的CR3,page table descriptor)來保證EL1,EL0不會影響到EL2的資料(isolation), EL1,EL2每層有自己的ttbr,所以page table mapping就有做好限制
- sctlr, system-mode暫存器(user mode不能存取),管控page table memory translation的部分, EL0,EL1想存取這個register時會trap到EL2,再由EL2看要怎麼處理
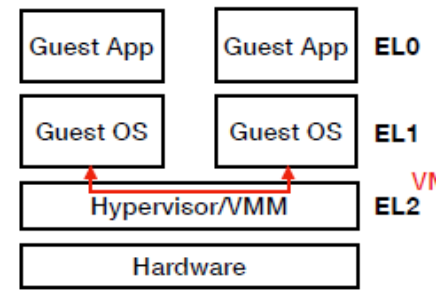
虛擬化Hypervisor(虛擬化EL2 or VT-X)
- 如果要nested VM時就需要這件事(VM內也會要有hypervisor)
Armv8 Architecture
- 架構:
- Application (EL0)
- RichOS (EL1)
- Hypervisor (EL2)
- Firmware (EL3)
- 31 general purpose register(x0 - x30), 64 bit each
- Special register: program counter, Stack pointer, Execption Link Register(ELR), Process Status Register(PSTATE,SPSR)
- PSTATE: 各種flags(ZF,DF等等的), masks, 控制當前CPU資訊
- SPSR: 存PSTATE的資料(exception發生時, 例如user轉kernel space之類的)
- System register
- Translation Table base(相當於page table base)
- paging/traps control
- control system software(OS,VMM,firmware)
- 用MSR這個instruction存取這些資訊
統整
CPU Virtualization
- virtual CPU map to physical cpu
- time-sharing(VM間的Context Switch) 來做vCPU的resource management
ISA Virtualization
- 保證VMM可以在這個新的CPU架構下以最高權限運行
- With Hardware Support
- 用CPU自己的方式來deprivilege這些VM
- Without Hardware support
- VM跑在User space, VMM跑在kernel space, 每次VM要跑privileged instruction就要trap, 所有問題都要用software trap & Emulate來處理. 例如VM執行power off, 實際上要做的不是真的在VMM執行這個指令, 而是VMM去修改VMCS的資料, 紀錄VM現在是power off
Memory Virtualization
關於Virtual Memory的部分講解可以先參考一下我關於Memory, Virtual Memory的posts. 這部分會更詳細的說明VMM如何透過硬體或軟體的解法來解決多個VM在memory端操作的問題. 基本上原本的Virtual Memory機制就已經能防護在同個OS下不同process存取記憶體的問題, 這裡要探討的是在VMM中不同VM如何存取硬體的Memory資源, 會更複雜在於VM本身自己內部也有自己的Processes和Virtual Memory, 而這個跟VMM或者Host的Virtual Address Space不同, 所以需要額外的Mapping機制, 但又要避免過多的Page table導致很多空間或時間的浪費, 而且要處理VM裡user space, kernel space不同process存取記憶體的權限.
Memory Introduction
可以去複習Page Table, Multi-level Page Table, TLB, Page Fault的概念. 硬體層面, MMU會去walk Page Table然後去找mappings.
整個流程是MMU會先去cache walk TLB, 如果cahce miss就會去Page Table找資料. Page table entry會記錄permission跟一些該memory block的設定.
Multi-level page table walk
因為現在通常空間很大, 例如64-bit address space所需的page table空間就超大, 所以幾個作法包括之前提過的hash table方式或者Multi-level page table.
下圖就是一個兩層的page table的例子, 第一層Page Table Directory(PGD), 裡面每個Entry會指向一個page Table. CR3是page table register, 會指向PGD的位置. 所以Virtual Address的部分就會是前面10個bit說是PGD的哪個entry, 然後就可以指向特定的Page Table, 而PT index就可以再從該Page table entry真正map到physical address. 而VA的offeset 12 bits代表一個page size是4K.
PGD mapping得到的address也是32 bit, 其中前面20 bit拿來指向Page Table address, 然後另外12 bit用來存該Page Table的一些Flags(權限之類的). 20-bit的PT address加上Virtual Address的10-bit PT-index就可以在當下那個Page table找到下個entry.
Page Table map出來的address也是32 bit, 20 bit用來指向physical address, 12 bit的flag bit. 20-bit的physical address再另外加上Virtual Address的12 bit offset剛好組成一個完整的32-bit Physical Address
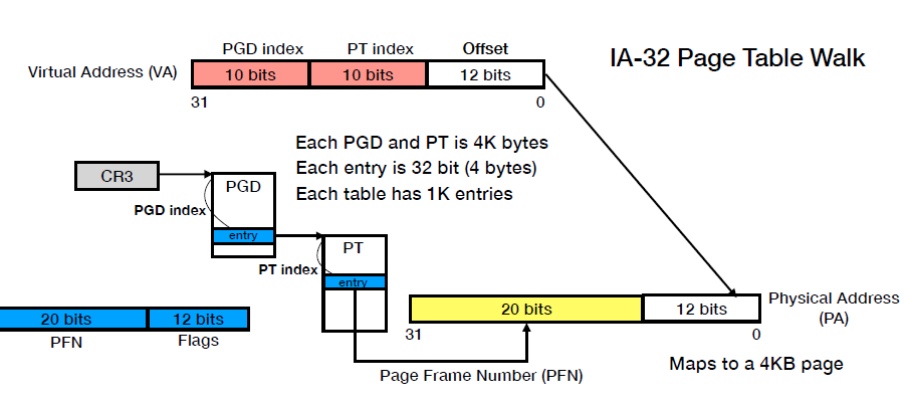
Multi-level page tables Virtualization
由此可知, 這種模式page table的overhead非常大, 因為很多page table. 因此如果某些layer的page table能夠share mapping, 那就不用每個process在那個layer還要多複製一個page table了. 例如3個VM裡的process都share同個第二層的page table mapping, 那第二層的page table只需要一個
Terminology
gva: Guest Virtual Address
GPT: Guest Page Table
gpa: Guest Physical Address
hpa: host physical Address
記憶體虛擬化的流程high-level來說就是會把gva轉成hpa, 中間可能透過某種table直接轉或者先把gva透過GPT轉成gpa, 最後再轉成hpa.
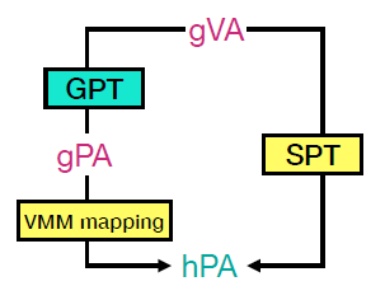
軟體解法: Shadow Page Table(SPT)
如上圖, Shadow page table由VMM提供, 為一個機制讓gva能夠直接轉成hpa.
- 直接存在VMM的memory裡, 也是一種page table, 因為架構一樣, 所以MMU可以用同樣的方式讀取資料不用更改, VMM就要扮演OS的角色, 當VM load/save gva時, VMM就會先walk GPT確定他valid, 然後再去SPT找他對應的位置.
- VM沒有權限access SPT(SPT可以想成基本上就是一種page table), VMM才能讀取修改
- guest VM有幾個page table, VMM就要有幾個spt(因為每個process的gva都不同), 而且要做好sync, 也就是VM一改動page table, VMM也要同時更新SPT. 所以VM的virtual CR3 pointer改變指向的GPT時, VMM也要更新自己的CR3指向相對應的SPT
- 因為有可能VM讓gva map到不同的gpa, 那這樣間接代表gva map到的實際hpa會不同. 所以要sync spt,gpt table, 代表要某種方式讓GPT一更新時會trap到VMM更新相對應的SPT, 一種做法是把GPT設成read-only. 這樣只要修改GPT就會trap到VMM, VMM就可以在Guest VM修改GPT時做相對應的修改.
- VMM要負責SPT的entry填入跟SPT page fault handling, VMM trap時會先去walk gva看一下這個address有沒有在GPT上, 沒有的話根本就非法memory address. 或者VMM walk SPT, 然後發現valid bit是0 所以開始page fault process, 傳signal給VM, 然後allocate記憶體給SPT,然後修改GPT update.
-
VMM模擬page fualt, 所以會傳signal給VM告訴他page fault, 然後依樣program counter改成VM OS的exectpion vector, CPU mode改成system mode(VM上).
- MMU支援user/supervisor(user/kernel mode)的page table access(即有些page table只有supervisor才能access), 因此SPT還要切成user-space跟kernel-space的entry. 有些entry user-space時是不能access的. 這樣變得很複雜而且SPT size也會變大.
優缺點
優點:
- memory translation快, 直接從gva轉成hpa
缺點:
- large overhead: SPT跟GPT要一值sync, 而且這都是很多的memory access
- 需要非常多的SPT, 而且如果考慮user/kernel mode memory access的問題, 實作會變難
硬體解法: Second Level Address Translation(SLAT): NPT, EPT
Intel, AMD使用NPT,EPT的方法, 就是上圖的左邊流程, 主要是幫助gPA轉成hPA的部分, 因為一個VM只會有一個Physical address, 所以這種做法的好處就是每個VM只要maintain一種Mapping, 而不是per process. 基本上想法很單純, 就是每次要作操作都把gva先轉成gpa再透過EPT/NPT table轉成hpa作運算, 因為轉成hpa後才能夠交給MMU作page walk.
具體而言, 例如今天要做一個gva到hpa的查詢, 首先會先要找到page directory(第一層page table), 作法就是先透過CR3配合GPT得到gpa, 再透過EPT table把gpa轉成hpa, 這樣就可以知道VM Page Directory的實體位置了, 接著第二層依樣作法, walk page directory, 找到entry到下一層的page table時, 也是把結果透過EPT table從gpa轉成hpa, 這樣就可以知道第二層page table的hpa了, 然後這樣查找最終會找到gva的對應hpa.
每次VMM initialize一個新的VM時, 就會allocate一個VM identifier(後面會提到,TLB用)跟NPT. 一開始NPT只含有少量entry(根據VM存取狀態, VMM不斷的NPT page fault, allocate hpa給gpa entry, demand paging)
NPT,EPT page fault機制一樣, 就由VMM來處理, hardware發現有問題就發page fault signal給VMM,VMM再根據狀況allocate或者signal VM. 會發生page fault原因在於physical memory本身有swapping機制(即physical memory使用量過高時可能部分block會被放到swap)
把gva轉成gpa的流程一樣是進行一個VM自己內部OS的page table look-up, 但問題點hardware只能看到hpa看不到gpa, gva轉成gpa的page table本身是存在gpa, 所以要先把GPT的gpa轉成hpa才能進行gva to gpa的page table lookup. 所以每次做gva to gpa轉換, 要先resolve GPT的hpa. 如果很不幸的gva到gpa是一個multi-layer page table, 那就是每層PT lookup到下層之前都要再一次把gpa轉成hpa (GPT會map到下一層的GPT, 但問題是因為都是在VM裡, 所以map到的address也是GPA, hardware要能去做下一層page table walk, 就要先把gpa轉成hpa). 更不幸的是gpa轉成hpa的NPT也不一定只有一層,而且通常也很多層, 因此假設GPT有n level, NPT有m level, 每找到一層的GPT需要m次memory access(NPT),總共n層, 所以需要n * m memory access, 外加每次找到GPT entry時的那次GPT access總共有n次, 而且最後得到的gpa在轉換成hpa要另外再加m次, 所以總共 n * m + n + m.
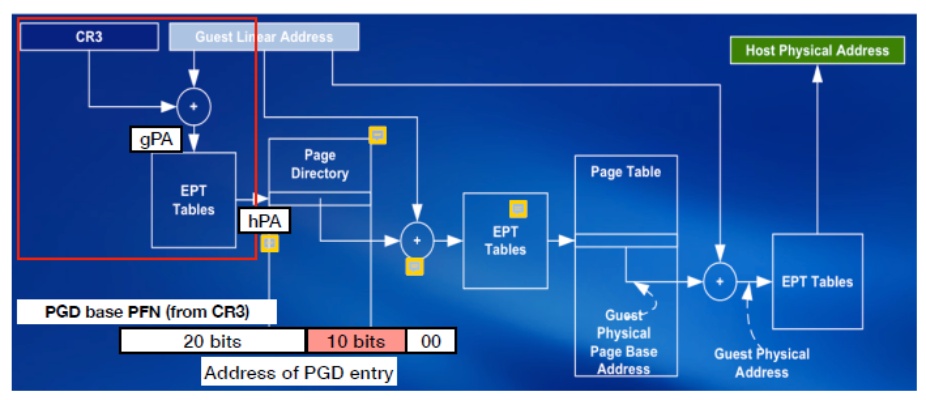
優缺點
優點:
- 不用再擔心VMM table跟VM table間sync的問題, 而且每個VM只要maintain一份table
- VMM變得比較單純, 不用sync table(GPT改也不太會影響NPT table), switch table
- Reduce memory footprint
缺點:
- 每次做gva to hpa會相對需要比較多的translation(一次translation要存取兩個page table(GTB,EPT), 假設TLB是存gva to hpa的mapping, 對TLB cache miss部分尤其傷(一次gva轉成hpa要n*m+n+m個PTE access, 假設n為GPT layer, m為EPT layer), 但就有各種不同cache機制來讓這些translation變快(cache某些mapping), 或者使用大的Page size(4KB變2MB), 這樣PT layer可能會少一些.
Shadow page table, nested Extended Page table
| Shadow Page Table | NPT/EPT | |
|---|---|---|
| VMM Complexity | High | Low |
| Memory Resource | High | Low |
| Page Table walk overhead | Low | High |
Architected Page Table and TLB
- Hardware實做記憶體循址的機制
- Architected TLB: 硬體只會看TLB, software只需要maintain TLB (透過TLP來直接va到pa的mapping, MIPS使用)
- Architected PT: OS只能管理page table, 硬體管理TLB(caching, 放entry), OS只能透過某些system call來管理(flsuhTLB之類的), 但沒有辦法填TLB entry
在TLB虛擬化就會是cache gva直接轉到hpa 或者gpa轉到hpa. 一個問題是hardware要能判斷TLB的entry分別屬於哪個VM的(不同VM可以有相同的pid, 所以單看pid不能判斷entry屬於哪個VM的), 一個做法就跟計組提到的每次vm switch就全flush, 另一個就是在家一個tag欄位存VMid, 所以TLB entry就會存VMid跟pid (Arm叫vmid, VT-x叫VPID), 然後VMM再透過一個特殊的暫存器存現在的VMid, 就知道現在在哪個vm下.
VM Bootstrapping
VMM就像是底層硬體提供VM bootstrap的程序, 提供CPU power管理服務, 模擬一些device info. 基本上跑一樣的OS bootstrap, VMM需要的話會讀取device info傳給VM, KVM甚至有boot loader可以選擇要bootload哪個OS.
boot loading有一個很重要步驟就是把一些要執行的firmware和boot loader放到VM的memory上(gpa), 所以VMM init VM時, NPT table上會含有少量的entry, 就是要跑的software, firmware, bootloader的gpa對hpa的mapping. 並且把PC設定好指向bootloader位址或者要跑的指令的gpa, 設定要跑的software的gpa.